Virtual Machine CPU Configuration
물리적, 가상, 논리적 CPU, 코어
먼저 용어부터 살펴보겠습니다. VMware는 VM 내의 프로세서와 기본 물리적 x86/x64 기반 프로세서 코어를 구분하기 위해 다음 용어를 사용합니다[20]:
- CPU: CPU 또는 프로세서는 컴퓨터 애플리케이션을 실행하는 데 필요한 작업을 수행하는 컴퓨터 시스템의 구성 요소입니다. CPU는 컴퓨터 기능을 수행하는 주요 요소입니다. CPU에는 코어가 포함되어 있습니다.
- CPU 소켓: CPU 소켓은 컴퓨터 마더보드의 물리적 커넥터로, 단일 물리적 CPU에 연결됩니다. 일부 마더보드에는 여러 개의 소켓이 있으며 여러 개의 멀티코어 프로세서(CPU)를 연결할 수 있습니다. “물리적 프로세서"와 “논리적 프로세서"를 명확히 구분할 필요가 있으므로 이 가이드에서는 업계 표준 관행을 따르며 “물리적 프로세서"를 의미하는 곳에는 “소켓"이라는 용어를 사용합니다.
- 코어: 코어에는 애플리케이션을 실행하는 데 필요한 L1 캐시 및 기능 유닛이 포함된 장치가 포함되어 있습니다. 코어는 애플리케이션 또는 스레드를 독립적으로 실행할 수 있습니다. 하나의 CPU에 하나 이상의 코어가 존재할 수 있습니다.
- 하이퍼스레딩 및 논리 프로세서: 하이퍼스레딩 기술을 사용하면 하나의 물리적 프로세서 코어가 두 개의 논리적 프로세서처럼 작동할 수 있습니다. 프로세서는 동시에 두 개의 독립적인 애플리케이션을 실행할 수 있습니다. 하이퍼스레딩 시스템에서 각 하드웨어 스레드는 논리적 프로세서입니다. 예를 들어, 하이퍼스레딩이 활성화된 듀얼 코어 프로세서에는 2개의 코어와 4개의 논리 프로세서가 있습니다[21]. 시각적 표현은 아래 그림 10을 참조하세요. 하이퍼스레딩은 유휴 리소스를 보다 효율적으로 사용하여 워크로드 성능을 향상시킬 수 있지만, 코어의 하이퍼스레드는 완전한 프로세서 코어가 아니며 코어처럼 작동하지 않는다는 점에 유의하는 것이 매우 중요합니다[22]. 이러한 인식은 컴퓨팅 리소스 할당 및 “적절한 크기 조정"에 대한 결정을 내릴 때 매우 유용합니다. 자세한 내용은 섹션 5.3을 참조하십시오.
그림 9. 물리적 서버 CPU 할당

예를 들어, 위의 그림 10에 나열된 호스트는 활성 하이퍼스레딩 구성의 결과로 2개의 p소켓(2개의 pCPU), 28개의 pCore 및 56개의 논리적 코어를 보유하고 있습니다. 하이퍼스레딩은 물리적 ESXi 호스트에서 해당 기능이 사용하도록 설정되어 있음을 ESXi가 감지하면 기본적으로 사용하도록 설정됩니다. 일부 공급업체는 시스템 BIOS에서 “Hyperthreading"을 “Logical Processor"로 지칭합니다.
- 가상 소켓 - 가상 머신에 할당된 가상 소켓의 수입니다. 각 가상 소켓은 가상화된 물리적 CPU 패키지를 나타내며 하나 이상의 가상 코어로 구성할 수 있습니다.
- 가상 코어 - 가상 소켓당 코어 수를 나타내며, vSphere 4.1부터 시작됩니다.
- 가상 CPU(vCPU) - VM에 할당된 가상화된 중앙 프로세서 유닛입니다. VM에 할당된 총 vCPU 수는 다음과 같이 계산됩니다:
총 vCPU = (가상 소켓 수)*(소켓당 가상 코어 수)
그림 10. 가상 머신 CPU 구성
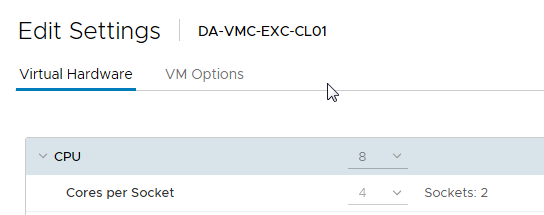
예를 들어, 그림 10에 표시된 가상 머신에는 각각 4개의 vCore가 있는 2개의 가상 소켓이 있으며, 총 vCPU 수는 8개입니다.
SQL Server 가상 머신에 vCPU 할당
성능이 SQL Server 설계의 최우선 순위인 경우 VMware는 초기 크기 조정 시 모든 가상 머신에 할당된 총 vCPU 수를 ESXi 호스트 시스템에서 사용 가능한 총 물리적 코어 수(논리적 코어 제외)를 넘지 않도록 권장합니다. 이 지침을 따르면 추가 워크로드에 사용할 수 있는 잠재적인 초과 용량을 파악할 수 있을 때까지 환경 내에서 성능 및 사용률을 측정할 수 있습니다. 예를 들어 SQL Server 워크로드가 실행되는 물리적 서버에 16개의 물리적 CPU 코어가 있는 경우 초기 가상화 작업 중에 해당 vSphere 호스트의 VM에 16개 이상의 가상 vCPU를 할당하지 않도록 합니다. 이러한 초기 보수적인 크기 조정 접근 방식은 가상화 프로젝트 도중 및 이후에 최적의 성능에 미치지 못하는 성능이 발생할 경우 발생할 수 있는 CPU 리소스 경합을 배제하는 데 도움이 됩니다. 사용 가능한 초과 용량이 있다고 판단되면 vSphere 클러스터에 더 많은 워크로드를 추가하고 사용 가능한 물리적 코어를 초과하는 가상 vCPU를 할당하여 해당 물리적 서버의 밀도를 높일 수 있습니다. 중장기 데이터 범위를 수집, 저장 및 분석할 수 있는 모니터링 툴을 사용하는 것도 고려할 수 있습니다.
일반적으로 하위 계층의 SQL Server 워크로드는 레이턴시에 덜 민감하므로 일반적으로 성능 극대화보다는 시스템 리소스 사용을 극대화하고 더 높은 통합 비율을 달성하는 것이 목표입니다.
vSphere CPU 스케줄러의 정책은 최대 처리량과 VM 간 공평성 간의 균형을 맞추도록 조정됩니다. 하위 계층 데이터베이스의 경우 합리적인 CPU 오버 커밋을 통해 전체 시스템 처리량을 늘리고 라이센스를 최대로 절약하며 충분한 성능을 계속 유지할 수 있습니다.
Hyper-threading[23]
하이퍼스레딩은 논리적 CPU라고도 하는 단일 물리적 코어에서 두 개의 하드웨어 컨텍스트(스레드)를 노출하는 인텔 기술입니다. 이는 CPU 또는 코어 수가 두 배인 것과는 다릅니다. 하이퍼스레딩은 프로세서 파이프라인을 더 바쁘게 유지하고 하이퍼바이저가 더 많은 CPU 스케줄링 기회를 가질 수 있도록 함으로써 일반적으로 전체 호스트 처리량을 최대 30%까지 향상시킵니다. 이러한 개선 사항과 함께 가상 환경(VM)의 대부분의 워크로드가 정기적으로 전체 컴퓨팅 리소스 할당을 동시에 요청하고 사용할 가능성이 거의 없다는 현실을 고려하면 vSphere에서 ESXi 호스트의 물리적 컴퓨팅 리소스를 2:1까지 초과 할당하는 것이 가능하고 지원되는 이유이기도 합니다. 이러한 초과 할당 방식을 따를 때는 광범위한 테스트와 우수한 모니터링 툴이 필요합니다.
VMware는 ESXi가 이 기술을 활용할 수 있도록 BIOS/UEFI에서 하이퍼 스레딩을 사용하도록 설정할 것을 권장합니다. ESXi는 vCPU를 물리적 코어에 매핑하는 것과 관련하여 신중한 CPU 관리 결정을 내리고 하이퍼 스레딩을 고려합니다. 가상 CPU가 4개인 가상 머신을 예로 들어 보겠습니다. 각 vCPU는 동일한 물리적 코어의 일부인 두 개의 논리적 스레드가 아닌 다른 물리적 코어에 매핑됩니다.
VMware는 vSphere에 오랫동안 존재했던 “Latency Sensitivity” 설정을 개선하기 위해 vSphere 8.0에 가상 하이퍼스레딩(vHT)을 도입했습니다. “Latency Sensitivity"를 제어할 수 있는 위치는 아래 이미지와 같이 vCenter의 VM 속성에 있는 “Virtual Hardware” 섹션에서 “VM Options” 탭의 “Advanced” 섹션으로 이동했습니다:
그림 11. VM에서 레이턴시 민감도 설정
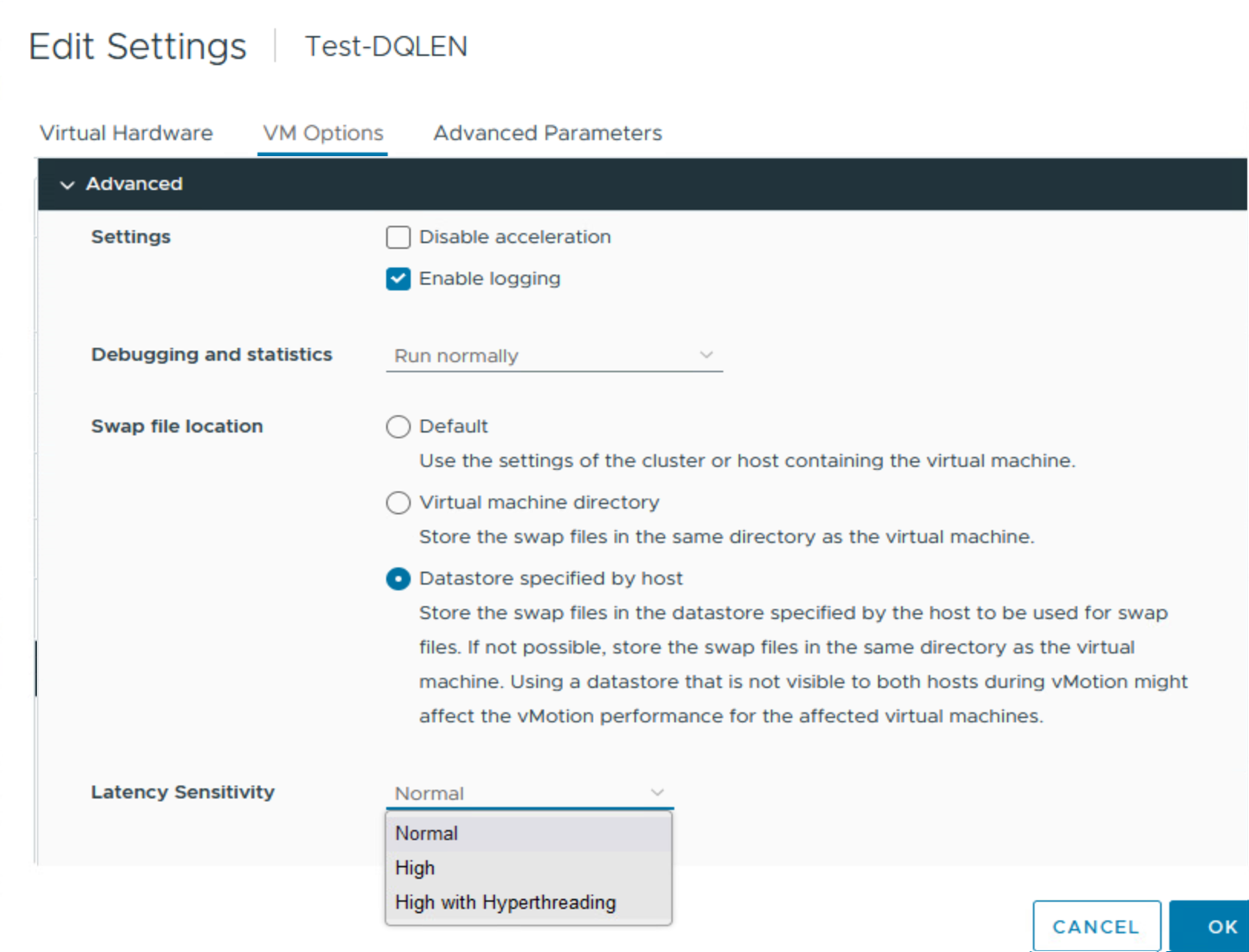
이제 “High with Hyperthreading” 옵션이 새롭게 추가된 것을 눈치채셨을 것입니다. Microsoft SQL Server와 같은 애플리케이션에서 지연 시간 민감도를 “High"으로 설정하면 전통적으로 상당한 성능 향상을 가져왔습니다.
“High with Hyperthreading” 옵션을 선택하면 이 이득은 더욱 증가합니다. 이 옵션을 선택하면 vSphere 환경에서 이러한 HT 인식 애플리케이션에 가상 HT를 사용할 수 있습니다. 성능 향상은 일반적으로 가상 머신에서 “Latency Sensitivity"를 “High"으로 설정할 때 물리적 CPU의 독점 예약(및 액세스)과 게스트 운영 체제 및 애플리케이션이 할당된 코어의 하이퍼스레드를 인식하는 기능의 조합으로 인해 발생합니다.
그림 12. “High with Hyperthreading"으로 독점 CPU 액세스 제공

ESXi에서 vHT가 활성화되지 않은 경우 각 가상 CPU(vCPU)는 게스트 운영 체제에서 사용할 수 있는 단일 비하이퍼스레드 코어와 동일합니다. vHT가 활성화된 경우 각 게스트 vCPU는 가상 코어(vCore)의 단일 하이퍼스레드로 취급됩니다.
동일한 vCore의 가상 하이퍼스레드는 동일한 물리적 코어를 차지합니다. 따라서 vHT가 비활성화되어 있는 레이턴시 민감도가 높은 VM에서 여러 개의 코어를 사용하는 것과는 달리 VM의 vCPU는 동일한 코어를 공유할 수 있습니다.
VM에서 “Latency Sensitivity"를 높음으로 설정하면 하이퍼바이저가 해당 VM에 대해 전체 리소스 예약을 사용하도록 설정하므로 클러스터의 다른 VM에서 사용할 수 있는 물리적 컴퓨팅 리소스의 양이 감소하므로 SQL Server 배포의 용량 계획 시 프로세서 스레드(논리적 코어)와 물리적 CPU/코어 간의 차이를 고려하는 것이 중요합니다. 높은 레이턴시 민감도는 다른 성능 튜닝 옵션이 해당 VM에 대해 효과가 없는 것으로 확인된 경우에만 신중하게 사용해야 합니다.
NUMA 고려 사항
지난 10년 동안 NUMA 기술과 그 구현에 대한 논의만큼 많은 관심을 끌었던 주제는 없었습니다. 이는 기술의 복잡성, 특히 공급업체 구현의 다양성, 구성 옵션의 수, 계층(하드웨어에서 하이퍼바이저, 게스트 OS 및 애플리케이션에 이르기까지)을 고려할 때 당연한 결과입니다. 사용 가능한 모든 구성 옵션에 대한 전체 개요를 제공하는 것처럼 가장하지 않고, vSphere 플랫폼에서 가상화된 Microsoft SQL Server 인스턴스와 같은 NUMA 인식 애플리케이션의 NUMA 관련 성능 지표를 개선하는 데 도움이 되는 중요한 지침을 제공하는 데 집중할 것입니다.
NUMA 이해[24]
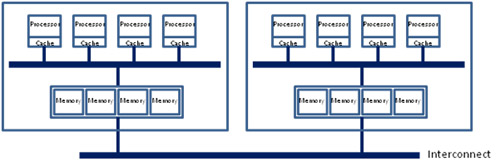
Non-uniform memory access (NUMA)는 공유 메모리를 위한 하드웨어 아키텍처로, pCPU 간에 물리적 메모리 뱅크의 세분화를 구현합니다(가능한 구현 중 하나는 그림 12 참조). NUMA를 지원하는 대칭형 멀티프로세싱(SMP) 시스템에는 일반적으로 처리 능력을 최대로 효과적이고 효율적으로 사용할 수 있도록 대량의 메모리 대역폭이 지원되는 프로세서 수가 밀집된(많은) 시스템 버스가 두 개 이상 있습니다. 대용량 메모리 대역폭이 없으면 이러한 고집적 시스템에서 실행되는 애플리케이션은 성능과 처리량에 제약을 받습니다. 데이터 버스 대역폭을 늘리면 이러한 제약을 어느 정도 완화할 수 있지만, 이 옵션은 비용이 많이 들고 확장성이 제한됩니다.
그림 13. 인텔 기반 NUMA 하드웨어 아키텍처[25]
이 문제에 대한 업계 표준 접근 방식은 버스를 더 작은 청크(노드)로 나누고 더 적은 수의 프로세서와 해당 사용 가능한 메모리 조각을 이러한 노드에 그룹화하는 것입니다. 이 그룹화는 노드의 프로세서와 메모리 간에 매우 효율적이고 고성능의 연결을 제공합니다. 프로세서가 실행하는 스레드, 명령어 및 프로세스가 동일한 노드에 상주하는 메모리에 의해 서비스될 때 이러한 프로세서에 액세스하는 애플리케이션의 성능이 훨씬 더 우수하고 최적화됩니다. 이러한 효율성과 성능 향상은 주로 프로세서가 주어진 명령어를 처리하기 위해 메모리를 가져오기 위해 시스템의 인터커넥트를 통과할 필요가 없기 때문에 명령어가 더 빠르게 실행되고 완료된다는 사실에서 비롯됩니다. 메모리 대역폭 요구 사항이 높은 애플리케이션의 경우 NUMA 인터커넥트 자체가 스로틀링 포인트가 될 수 있다는 점을 고려할 때, NUMA 시스템에서 로컬 메모리로 실행 명령을 서비스하는 것이 원격 노드의 메모리로 서비스하는 것보다 저렴하고 더 좋습니다.
이 아키텍처는 궁극적인 이점이 있지만 고려해야 할 몇 가지 단점도 있습니다. 가장 중요한 것은 요청을 실행하는 CPU 코어에 대한 해당 메모리 캐시 라인의 로컬 또는 원격 배치에 따라 서로 다른 메모리 캐시 라인의 데이터에 액세스하는 시간이 달라지며, 원격 액세스가 로컬보다 최대 X[26] 배 느리다는 점입니다. 이 때문에 전체 아키텍처에 균일하지 않은 이름이 붙었으며, NUMA를 구현하는 하드웨어 위에 배포된 모든 애플리케이션의 주요 관심사입니다.
단일 소켓에 물리적으로 사용 가능한 것보다 많은 수의 vCPU가 할당된 경우(흔히 “wide VM"이라고 설명하는 조건) ESXi NUMA 스케줄러가 자동으로 최적의 효율적인 NUMA 토폴로지를 감지하여 VM에 제시할 수 있지만, vSphere 관리자는 이러한 제시를 수동으로 검토하여 워크로드 요구 사항 및 기업 시스템 관리 관행을 충족하는지 확인하는 것이 좋습니다.
이 또한 중요한데, NUMA가 활성화되어 있더라도 특히 가상 환경에서는 워크로드 또는 애플리케이션에 도움이 되는 방식으로 자동으로 구성되지 않기 때문입니다. 수년에 걸쳐 VMware는 ESXi에서 NUMA 기능 구현을 지속적으로 개선해 왔으며, 이러한 발전을 고려하여 VM에 대한 메모리 및 CPU 할당을 적절하게 구성하는 방법에 대한 지침도 주기적으로 변경되었습니다. 여기에서는 다양한 계층의 NUMA 구현을 살펴보고 vSphere에서 실행되는 대부분의 SQL Server 워크로드에 적합한 권장 사례를 제공합니다. 모든 워크로드가 동일한 것은 아니므로 특정 구현에 대해서는 광범위한 테스트와 모니터링을 적극 권장합니다. 특수한 고성능에 최적화된 SQL Server 배포의 경우 이러한 일반 지침의 범위를 벗어나는 사용자 지정 설정을 사용해야 할 수 있습니다.
ESXi NUMA 스케줄링 작동 방식[27]
ESXi는 정교한 NUMA 스케줄러를 사용하여 프로세서 로드와 메모리 로컬리티 또는 프로세서 로드 밸런스의 균형을 동적으로 조정합니다.
- NUMA 스케줄러가 관리하는 각 가상 머신에는 홈 노드가 할당됩니다. 홈 노드는 시스템 리소스 할당 테이블(SRAT)에 표시된 대로 프로세서와 로컬 메모리를 포함하는 시스템의 NUMA 노드 중 하나입니다.
- 가상 시스템에 메모리가 할당될 때 ESXi 호스트는 홈 노드에서 우선적으로 메모리를 할당합니다. 가상 시스템의 가상 CPU는 메모리 로컬리티를 최대화하기 위해 홈 노드에서 실행되도록 제한됩니다.
- NUMA 스케줄러는 시스템 부하 변화에 대응하기 위해 가상 머신의 홈 노드를 동적으로 변경할 수 있습니다. 스케줄러는 프로세서 로드 불균형을 줄이기 위해 가상 머신을 새 홈 노드로 마이그레이션할 수 있습니다. 이로 인해 더 많은 메모리가 원격으로 이동될 수 있으므로 스케줄러는 메모리 로컬리티를 개선하기 위해 가상 머신의 메모리를 새 홈 노드로 동적으로 마이그레이션할 수 있습니다. 전체 메모리 로컬리티를 개선하기 위해 NUMA 스케줄러는 노드 간에 가상 머신을 스왑할 수도 있습니다.
Sub-NUMA Clustering(Cluster-on-Die)
앞서 ESXi 호스트의 NUMA 토폴로지는 일반적으로 물리적 CPU 소켓 및 메모리 토폴로지를 미러링한다고 언급했습니다. 소켓이 2개인 물리적 마더보드에는 일반적으로 2개의 NUMA 노드가 포함될 것으로 예상할 수 있습니다. 이는 “Cluster on Die(CoD)” 또는 “Sub-NUMA Clustering(SNC)“이라는 최신 CPU 기술에서 그리 새롭지 않은 기능 세트의 인기가 높아지는 것을 고려하기 전까지는 대체로 사실입니다.
두 가지 명칭 모두 각 CPU 소켓을 더 작은 단위(또는 노드)로 세분화하여 시스템에서 더 많은 성능을 끌어내기 위한 CPU 공급업체의 노력을 나타냅니다. 이 섹션을 읽으면서 ESXi 스케줄러는 가상 머신에 표시되는 각 NUMA 노드에 대해 NUMA 클라이언트를 생성한다는 점에 유의하십시오. ESXi는 내부적으로 이러한 클라이언트를 사용하여 VM의 성능을 최적화하며, ESXi CPU 스케줄러는 해당 VM의 성능을 개선할 수 있다고 판단될 때마다 이러한 클라이언트를 이동(밸런싱 재조정)할 수 있습니다(실제로도 이동). 기본적으로 스케줄러는 VM의 NUMA 클라이언트를 가능한 한 서로 가깝게 배치하지만, 특히 호스트에서 리소스 경합이 발생하는 경우 스케줄러는 지원되는 NUMA 클라이언트를 백그라운드에서 마이그레이션할 수 있습니다. NUMA 클라이언트 마이그레이션은 관리자에게는 투명하지만 VM의 성능에 적지 않은 악영향을 미칠 수 있습니다. vSphere 인프라에서 최적의 상태는 NUMA 클라이언트 마이그레이션이 가능한 한 적은 경우입니다.
서버 하드웨어 및 컴퓨팅 리소스 용량이 점점 더 커지고 밀도가 높아지고 가상화된 비즈니스 크리티컬 워크로드가 표준 배포 및 구성 관행으로 물리적 인스턴스를 대체함에 따라 애플리케이션 소유자는 대형 VM(일명 “Monster VM”)을 적게 생성하거나 더 작은 VM을 많이 생성하는 것 중에서 하나를 선택해야 했습니다. 호스팅하는 애플리케이션에 대해 더 큰 단일 장애 지점을 생성하는 반면, 더 작은 여러 인스턴스에 애플리케이션을 분산하여 단일 시스템 장애가 나머지 인프라에 미치는 영향을 줄이는 것과 같이, 더 적은 수의 VM으로 동일한 운영 효율성을 관리할 수 있다는 주장이 있습니다.
vSphere 환경에 SQL Server를 배포하는 대부분의 고객은 일반적으로 워크로드에 더 크고 밀집된 가상 머신을 선택합니다. 일부는 관리 효율성 목적으로, 다른 일부는 라이센싱 고려 사항으로 이를 선택합니다. 더 큰 가상 머신을 선택하는 이유와 관계없이 이러한 구성 선택에 대한 CoD/SNC의 영향을 이해하는 것이 중요합니다.
VMware 참조 아키텍처 문서 및 모범 사례 권장 사항에서는 VM에 할당된 컴퓨팅 리소스가 가능한 한 적은 수의 NUMA 노드에 들어갈 수 있도록 VM의 “right-size"를 지정해야 한다고 설명합니다. 이는 애플리케이션과 시스템이 일반적으로 CPU와 메모리의 인접성이 가까울수록 더 나은 성능을 발휘하기 때문입니다. 특정 CPU 명령을 처리하는 메모리가 명령을 내리는 CPU에 가까우면 명령이 더 빨리 완료됩니다.
관리자는 일반적으로 물리적 하드웨어 레이아웃에 대한 지식(및 ESXi에서 제공하는 정보)을 사용하여 호스트의 NUMA 토폴로지를 추론합니다. CoD/SNC는 “실제” NUMA 토폴로지를 더 작게 분할하여 물리적 토폴로지와 다른(그리고 이보다 더 작은) NUMA 토폴로지를 생성합니다. CoD/SNC 토폴로지는 vSphere 클라이언트에서 표시되지 않으므로 관리자는 이 토폴로지를 볼 수 없으므로 가상 머신에 표시되는 NUMA 토폴로지는 가상 머신에 실제로 표시되는 것과 다를 수 있습니다.
이러한 구성 차이로 인해 적절한 크기의 VM이 토폴로지를 상속하게 되어 SQL Server와 같은 애플리케이션의 성능이 최적화되지 않는 상황이 발생할 수 있습니다. 예를 들어 이를 설명해 보겠습니다.
이 예에서는 Dell PowerEdge R750(인텔 제온 골드 6338 CPU 2.00GHz) 서버를 사용하고 있습니다. 이 호스트에는 2개의 CPU 소켓, 각 소켓의 32코어, 512GB 메모리로 구성된 2개의 물리적 CPU 패키지가 있습니다. 일반적으로 각 소켓은 총 사용 가능한 메모리(256GB)의 절반에 인접합니다. 예를 들어, 이렇게 하면 2개의 물리적 NUMA 노드가 효과적으로 생성되며, 이 노드는 ESXi 하이퍼바이저까지 통신됩니다.
설명한 대로 최대 32개의 가상 CPU와 256GB RAM이 할당된 VM은 단일 NUMA 노드에 적합하며, 예를 들어 34개의 가상 CPU와 312GB RAM이 할당된 VM보다 더 효율적으로 작동할 것으로 기대할 수 있습니다.
이 ESXi 호스트에서 CoD/SNC를 사용하도록 설정하면 각 NUMA 노드가 2개로 더 분할되어 각각 16개의 코어와 128GB 메모리를 갖춘 4개의 NUMA 노드로 구성된 클러스터가 생성됩니다.
이 예에서 최대 16개의 가상 CPU와 128GB RAM이 할당된 VM은 단일 NUMA 노드에 적합하며, 이 조건에서는 원격 메모리 가져오기가 발생하지 않으므로 정상적인 작동 조건에서 최적의 성능을 기대할 수 있습니다.
20개의 가상 CPU와 128GB RAM이 있는 VM은 SNC/CoD가 활성화된 상태에서 NUMA 노드에는 16개의 vCPU만 있는 반면 VM에는 20개가 있기 때문에 프로세스에 필요한 메모리 중 일부를 원격 NUMA 노드에서 가져오도록 강제됩니다.
실제로 일부 애플리케이션은 CoD/SNC를 통해 이점을 얻을 수 있지만, VMware는 vSphere의 대규모 Microsoft SQL Server 워크로드에서 이러한 성능 이점을 관찰하지 못했습니다. 따라서 VMware는 고객이 ESXi 호스트에서 “Cluster-on-Die” 또는 “Sub-NUMA Clustering” 기능의 사용 여부를 결정할 때 애플리케이션 및 비즈니스 요구 사항에 대한 광범위한 테스트와 검증을 수행할 것을 강력히 권장합니다.
고객은 특히 특정 조건에서 SNC/CoD를 사용하도록 설정하면 ESXi 하이퍼바이저가 ESXi 호스트에서 호스팅되는 대규모 VM에 원하지 않는 가상 NUMA 토폴로지를 제공할 수 있다는 점에 유의해야 합니다.
SNC/CoD를 사용하도록 설정한 경우 VMware는 고객이 하위 NUMA 노드의 코어 크기 배수(예제에서는 16, 32, 48)로 대형 VM에 가상 CPU를 할당할 것을 권장합니다.
vSphere 8의 새로운 vNUMA 옵션 이해[28]
vSphere 8.0의 출시와 함께 VMware는 하이퍼바이저가 VM에 NUMA 토폴로지를 제공하는 방식을 크게 개선하고 변경했으며, 이러한 변경 사항은 가상 머신의 게스트 운영 체제가 할당된 vCPU를 보고 소비하는 방식에 영향을 미칩니다.
ESXi는 역사적으로 NUMA 토폴로지를 VM에 노출할 수 있었습니다. 가상 머신에 8개 이상의 가상 CPU가 할당되면 해당 가상 머신에서 가상 NUMA(vNUMA)가 자동으로 활성화되어(이 최소 임계값인 8개 vCPU는 관리적으로 구성 가능) VM의 게스트 OS 및 애플리케이션이 이러한 토폴로지 인식으로 제공되는 성능 개선의 이점을 활용할 수 있습니다.
이 기능은 vSphere 8.0에서 더욱 세분화되고 개선되었습니다. 과거에는 vNUMA가 VM에 할당된 메모리 크기나 가상 소켓 및 소켓당 코어 수를 고려하지 않고 해당 VM에 노출된 vNUMA 토폴로지를 계산했지만, 새로운 vNUMA 알고리즘 및 로직은 이러한 구성을 고려합니다. 기본적으로 ESXi 8.0은 이제 vNUMA 토폴로지를 자동 구성할 때 가상 메모리 할당을 고려하며, 할당된 소켓당 코어 수와 토폴로지를 지원하기 위한 최적의 L3 캐시 크기를 제공해야 하는 필요성의 조합에 따라 결과 표시가 영향을 받습니다.
NUMA 사용
이전 섹션에서 언급했듯이, NUMA 아키텍처를 사용하면 해당 애플리케이션이 NUMA를 인식하는 경우 애플리케이션의 성능에 긍정적인 영향을 줄 수 있습니다. SQL Server Enterprise 에디션은 SQL Server 2005 버전부터 기본 NUMA를 지원하므로(일부 제한 사항이 있지만 SQL Server 2000 SP3에서도 사용 가능)[29], 궁극적으로 최신 SQL Server의 거의 모든 배포에서 적절하게 구성된 NUMA 프레젠테이션의 이점을 누릴 수 있습니다[30].
이 점을 염두에 두고 이제 가상 머신에서 실행되는 SQL Server 인스턴스에 올바르고 예상되는 NUMA 토폴로지가 표시되도록 보장하는 방법을 살펴보겠습니다.
물리적 서버 하드웨어
NUMA 지원은 CPU 아키텍처에 따라 달라지며, AMD 옵테론 시리즈에서 처음 도입된 후 2008년에 인텔 네할렘 프로세서 제품군에서 도입되었습니다. 현재 시중에서 판매되는 거의 모든 서버 하드웨어는 NUMA 아키텍처를 사용하지만, 공급업체 및 하드웨어에 따라 서버의 BIOS에서 NUMA 기능이 기본적으로 활성화되어 있을 수도 있습니다. 따라서 관리자는 ESXi 호스트의 하드웨어 BIOS 설정에서 NUMA 지원이 사용하도록 설정되어 있는지 확인하는 것이 좋습니다. 대부분의 하드웨어 벤더는 이 설정을 “Node interleaving”(HPE, Dell) 또는 “Socket interleave”(IBM)라고 부르며, 이 설정을 “disabled” 또는 “Non-uniform Memory access (NUMA)[31]“로 설정해야 NUMA 토폴로지를 노출할 수 있습니다.
경험상 노출되는 NUMA 노드 수는 인텔 프로세서의 경우 물리적 소켓 수와 같으며[32], AMD 프로세서의 경우 두 배입니다. 자세한 내용은 서버 설명서를 참조하세요.
VMware ESXi 하이퍼바이저 호스트
vSphere는 버전 2부터 물리적 서버에서 NUMA를 지원합니다. 현재 버전(이 문서 작성 시점 기준 8.0)으로 이동하면서 특히 “Wide” VM의 경우 NUMA 토폴로지를 관리하는 데 도움이 되는 몇 가지 구성 옵션이 도입되었습니다. 이 문서의 궁극적인 목표는 NUMA 토폴로지가 SQL Server를 호스팅하는 VM에 노출되는 방식에 대한 명확한 지침을 제공하는 것이므로 모든 고급 설정에 대한 설명은 생략하고 필요한 예제 및 관련 구성에 집중할 것입니다.
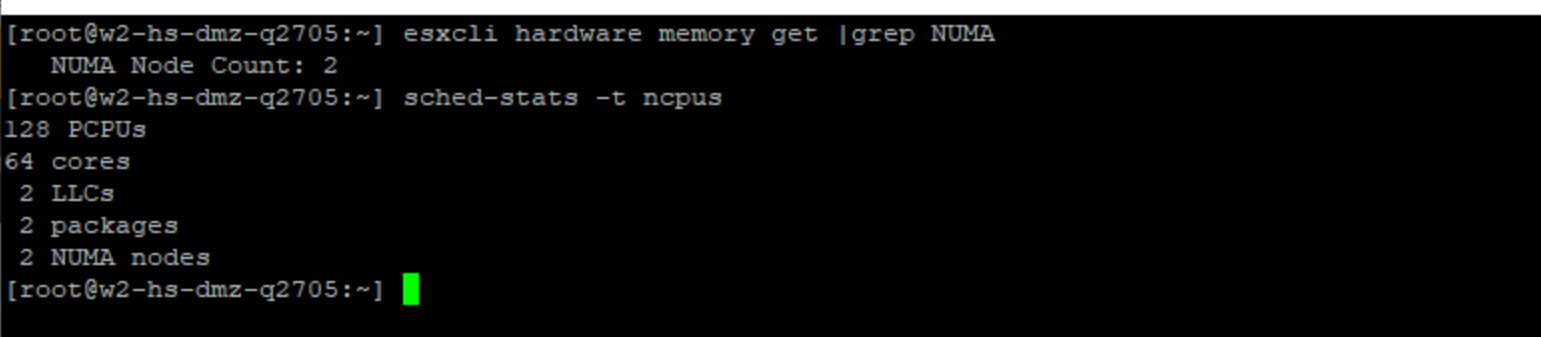
이 목표를 달성하기 위한 첫 번째 단계는 물리적 NUMA 토폴로지가 ESXi 호스트에 올바르게 노출되는지 확인하는 것입니다. 이 정보를 얻으려면 esxtop 또는 esxcli 및 sched-stats를 사용합니다:
esxcli hardware memory get | grep NUMA
sched-stats -t ncpus그림 14. esxcli 또는 sched-stats를 사용하여 ESXi 호스트에서 NUMA 노드 수 가져오기
또는
esxtop에서 메모리를 위해 M을 누르고, 필드를 조정하려면 F를, NUMA 통계를 활성화하려면 G를 누릅니다[33],
그림 15. esxtop을 사용하여 ESXi 호스트에서 NUMA 관련 정보 얻기

둘 이상의 NUMA 노드가 ESXi 호스트에 노출된 경우 VMkernel에서 “NUMA scheduler"를 사용하도록 설정합니다. NUMA 홈 노드(물리적 NUMA 노드의 논리적 표현으로, pNUMA에 할당된 코어 수와 메모리 양을 노출)와 NUMA 클라이언트(NUMA 홈 노드당 가상 머신당 하나)가 각각 생성됩니다[34].
가상 머신을 예약하는 데 필요한 NUMA 클라이언트 수가 두 개 이상인 경우 해당 가상 머신은 “wide VM"으로 참조되며 vSphere 버전 5.0 이상부터 이 가상 머신에 가상 NUMA(vNUMA) 토폴로지가 노출됩니다. 이 정보는 게스트 OS 및 SQL Server 인스턴스에서 각 NUMA 구성을 생성하는 데 사용됩니다. 따라서 vNUMA 토폴로지가 생성되는 방식과 이에 영향을 줄 수 있는 설정을 이해하는 것이 매우 중요합니다.
vSphere 8.0에 도입된 인상적인 NUMA/vNUMA 기능 중 하나는 관리자가 VM에 대한 NUMA/vNUMA 프레젠테이션을 보다 세부적으로 정의할 수 있는 GUI 옵션이 제공된다는 점입니다. 이 기능을 살펴보고 원하는 최종 상태 및 성능 요구 사항에 대한 적용 가능성 및 적합성을 판단해 보시기 바랍니다.
vSphere 6.5부터는 vNUMA 생성이 다른 로직을 따르게 되므로 별도로 분석하고 예제를 사용하여 차이점을 살펴보겠습니다. 모든 설정은 별도로 언급되지 않는 한 해당 vSphere 버전의 기본값으로 처리됩니다:
일반 규칙(현재 지원되는 모든 vSphere 버전에 적용됨):
- ESXi가 vNUMA를 VM에 노출하는 최소 vCPU 임계값은 9입니다. VM에 8개를 초과하는 vCPU가 있으면 가상 NUMA가 해당 VM에 노출됩니다.
- 참고: 이 임계값은 관리적으로 구성할 수 있습니다. 관리자는 VM의 고급 구성에서 원하는 값으로 고급 VM 구성 매개 변수 값인 “numa.vcpu.min"을 설정하면 할당된 vCPU 수가 이 값을 초과하면 해당 VM에 가상 NUMA를 노출하도록 ESXi에 지시할 수 있습니다.
- 가상 NUMA가 활성화된 가상 머신의 전원을 처음 켜면 해당 가상 NUMA 토폴로지는 기본 물리적 호스트의 NUMA 토폴로지를 기반으로 합니다. 가상 머신의 가상 NUMA 토폴로지가 초기화되면 해당 가상 머신의 vCPU 수가 변경되지 않는 한 변경되지 않습니다.
- 참고: 이 동작은 클러스터 수준의 EVC(향상된 vMotion 호환성)[35] 기능을 사용하여 서로 다른 물리적 NUMA 토폴로지를 가진 ESXi 호스트를 단일 vSphere 클러스터에서 함께 그룹화할 때 염두에 두어야 할 매우 중요한 사항입니다.
- 전원을 켠 후 VM의 vNUMA 토폴로지가 재평가되지 않으므로 실행 중인 VM을 한 호스트에서 다른 NUMA 토폴로지를 가진 다른 호스트로 마이그레이션해도 VM에서 노출된 토폴로지가 변경되지 않습니다. 이로 인해 VM이 새 ESXi 호스트에서 다시 시작될 때까지 NUMA 불균형 및 성능 저하가 발생할 수 있습니다.
- EVC는 VM 수준 구성 속성으로도 사용할 수 있습니다. VM 수준에서 EVC를 구성하면 클러스터 수준 EVC 설정이 재정의됩니다. VM 수준 EVC가 설정된 VM은 재부팅 후에도 새 호스트의 EVC 모드를 상속할 수 없습니다. VM 수준 EVC가 새 호스트의 EVC 모드와 호환되도록 하려면 수동 재구성이 필요합니다.
- NUMA/vNUMA는 CPU/vCPU와 메모리의 조합 함수이지만 vSphere는 vNUMA를 VM에 노출할 때 VM의 할당된 메모리나 소켓당 코어 수 또는 가상 소켓을 고려하지 않습니다.
- 참고: VM에 할당된 vCPU 및 메모리가 하나의 물리적 NUMA 노드에 맞을 수 있는 경우 ESXi는 vNUMA를 VM에 노출하지 않습니다.
- 할당된 vCPU가 하나의 물리적 소켓에 들어갈 수 있지만 할당된 메모리가 해당 소켓에서 사용할 수 있는 메모리를 초과하는 경우 ESXi 스케줄러는 비로컬 메모리를 수용하는 데 필요한 만큼의 스케줄링 토폴로지를 생성합니다. 이 자동 생성된 구조는 게스트 OS에 노출되지 않습니다.
- 앞서 설명한 내용에는 VM/Guest OS 내부의 애플리케이션이 NUMA 경계를 넘어 원격 메모리에서 서비스되는 명령 및 프로세스에 의존해야 하는 상황이 포함되며, 이로 인해 심각한 성능 저하가 발생할 수 있습니다.
- 이전 섹션에서 설명한 문제는 이제 가상 NUMA 토폴로지 정의 GUI의 도입으로 vSphere 8.0에서 효과적으로 해결되었습니다.
- 기존에는 VM에서 “CPU Hot add” 기능이 활성화된 경우 vNUMA가 노출되지 않았습니다. 이 동작은 vSphere 8.0에서도 변경되었습니다(아래의 “CPU Hot Plug” 섹션 참조).
- vNUMA를 게스트 OS에 노출하려면 VM 가상 하드웨어 버전 8이 필요합니다. 그러나 앞서 설명한 내용과 이 문서의 다른 부분에서 설명한 vSphere 8.0의 새로운 개선 사항은 가상 하드웨어 버전이 20 이상인 경우에만 VM에서 사용할 수 있습니다.
- VM의 CPU 구성이 변경되면 vNUMA 토폴로지가 업데이트됩니다. 변경 시점에 시작된 VM이 있는 호스트의 pNUMA 정보가 vNUMA 토폴로지를 생성하는 데 사용됩니다.
vSphere 버전 6.5 이상
VMware는 vSphere 6.5에 자동 vNUMA 프레젠테이션을 도입했습니다. 앞서 언급했듯이 이 기능은 적격 가상 머신에서 vNUMA 토폴로지를 생성하는 동안 “Cores per Socket” 설정을 고려하지 않았습니다. VM의 최종 vNUMA 토폴로지는 VM이 시작될 물리적 호스트의 CPU 패키지당 물리적 코어 수를 사용하여 계산됩니다. VM에 할당된 총 vCPU 수는 CPU 패키지 크기와 동일한 최소 PPD(근접 도메인) 수로 통합됩니다. 대부분의 사용 사례(및 대부분의 워크로드)에서 자동 크기 조정을 사용하면 이전 방식에 비해 더욱 최적화된 구성을 생성할 수 있습니다.
이제 vSphere 8.0에서 VMware vSphere 관리자는 직관적인 방식으로 VM과 해당 게스트 OS 및 애플리케이션에 대해 원하는 NUMA 토폴로지를 수동으로 구성하고 ESXi에서 결정한 자동 NUMA 구성을 재정의할 수 있습니다. 관리자는 SQL Server 관리자 및 기타 이해 관계자와 긴밀히 협력하여 애플리케이션의 사용 현황 및 특정 요구 사항을 파악하여 아래 섹션에 규정된 권장 사항이 특정 사용 상황에 미치는 영향을 평가하고 결정해야 합니다.
“Wide” Microsoft SQL Server VM을 위한 가상 NUMA 구성
vSphere 8.0에서는 표준 CPU 토폴로지 표시가 변경되었습니다. 이러한 변경 사항의 대부분은 이 문서의 다른 부분에서 설명했습니다. 이 세션에서는 vSphere 환경에서 가상화된 SQL Server 인스턴스에 대한 NUMA 기반 성능 메트릭을 개선하기 위한 권장 사항을 소개합니다.
VM에 할당된 컴퓨팅 리소스(메모리 및/또는 CPU)가 ESXi 호스트의 물리적 NUMA에서 사용할 수 있는 것보다 많은 경우 관리자는 호스트의 물리적 NUMA 토폴로지와 유사하게 이 프레젠테이션을 수동으로 조정하는 것을 고려하는 것이 좋습니다. 할당된 메모리 또는 vCPU가 단일 물리적 NUMA 노드에 맞지 않는 한 VM은 “Wide"로 간주된다는 점을 기억하는 것이 중요합니다. 이해를 돕기 위해 이제 예시를 통해 이를 설명하겠습니다.
언제 “와이드"로 간주되나요?
그림 16. 언제 “와이드"로 간주되나요?
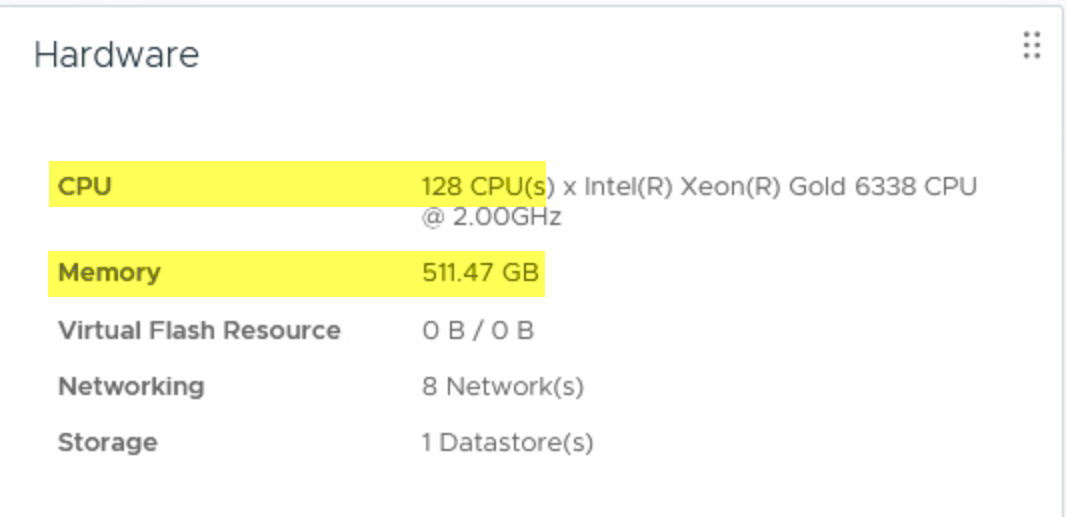
ESXi 호스트에는 128개의 논리적 CPU(각각 32개의 코어가 있는 2개의 소켓, 하이퍼스레딩이 활성화됨)가 있습니다.
또한 512GB의 메모리가 있습니다.
예 1
16개의 vCPU와 128GB RAM이 있는 비와이드 VM을 생성하고 전원을 켜면 ESXi가 vNUMA가 VM에 자동으로 노출되는 최소 vCPU 임계값을 초과했지만 할당된 모든 컴퓨팅 리소스가 단일 NUMA 노드에 들어갈 수 있으므로 “Wide” VM이 아니라고 판단하는 것을 알 수 있습니다. 결과적으로 ESXi는 아래 그림과 같이 VM에 UMA를 제공합니다.
그림 17. VM의 vCPU가 NUMA 노드에 적합할 때 UMA 토폴로지를 생성하는 ESXi
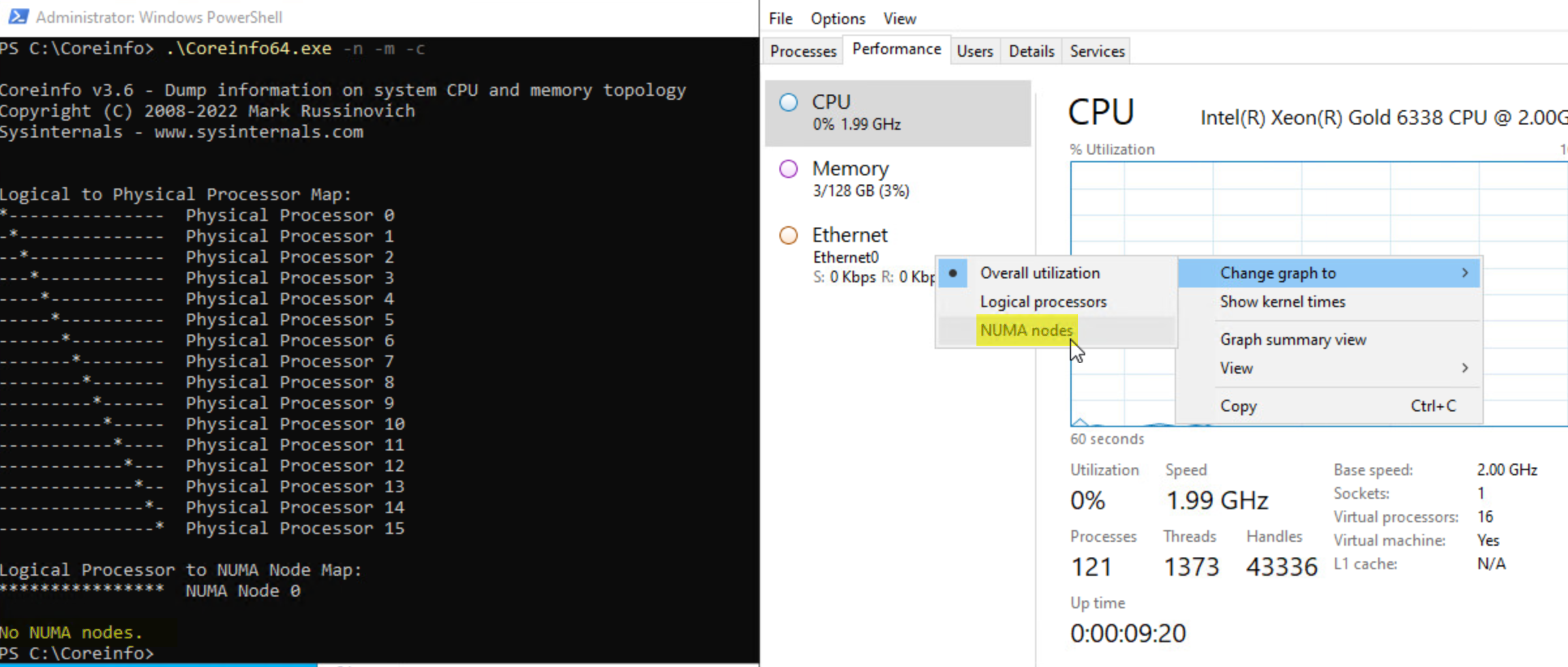
또한 이 경우 수동으로 변경하는 것이 기술적 이점이 없기 때문에 수동으로 변경하지 않기로 결정했습니다.
그림 18. ESXi가 비와이드 가상 머신에 대해 자동으로 vNUMA 토폴로지를 결정하도록 함
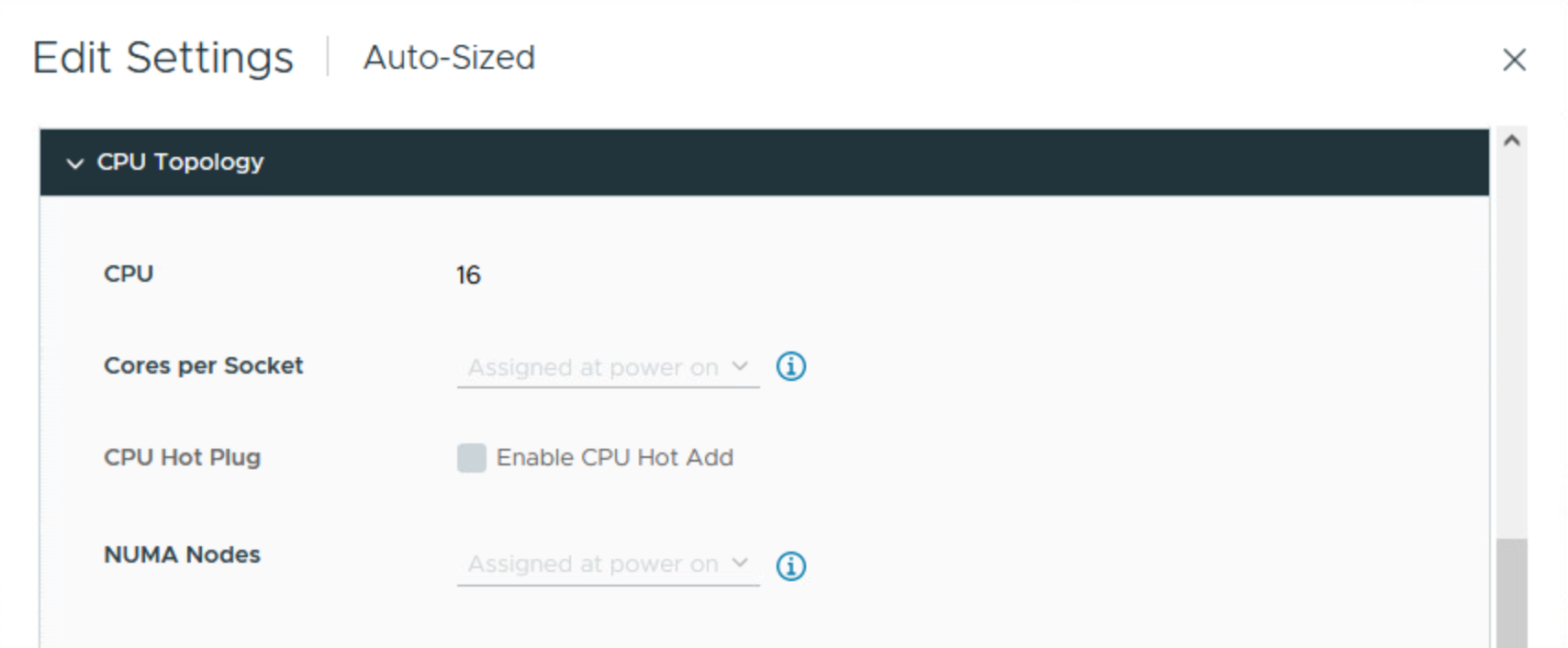
예 2
이제 VM의 메모리 크기를 384GB로 조정하고 vCPU를 변경하지 않고 그대로 두면(예: 16개의 vCPU) ESXi는 여전히 UMA 구성을 표시하지만 약간의 문제가 발생합니다. VM에 할당된 메모리가 물리적 NUMA 노드에서 사용 가능한 메모리 용량(256GB)을 초과했기 때문에 “초과” VM 메모리는 다른 물리적 노드에서 할당됩니다.
그림 19. ESXi가 메모리 전체 VM에 대해 vNUMA 토폴로지를 자동으로 결정하도록 허용
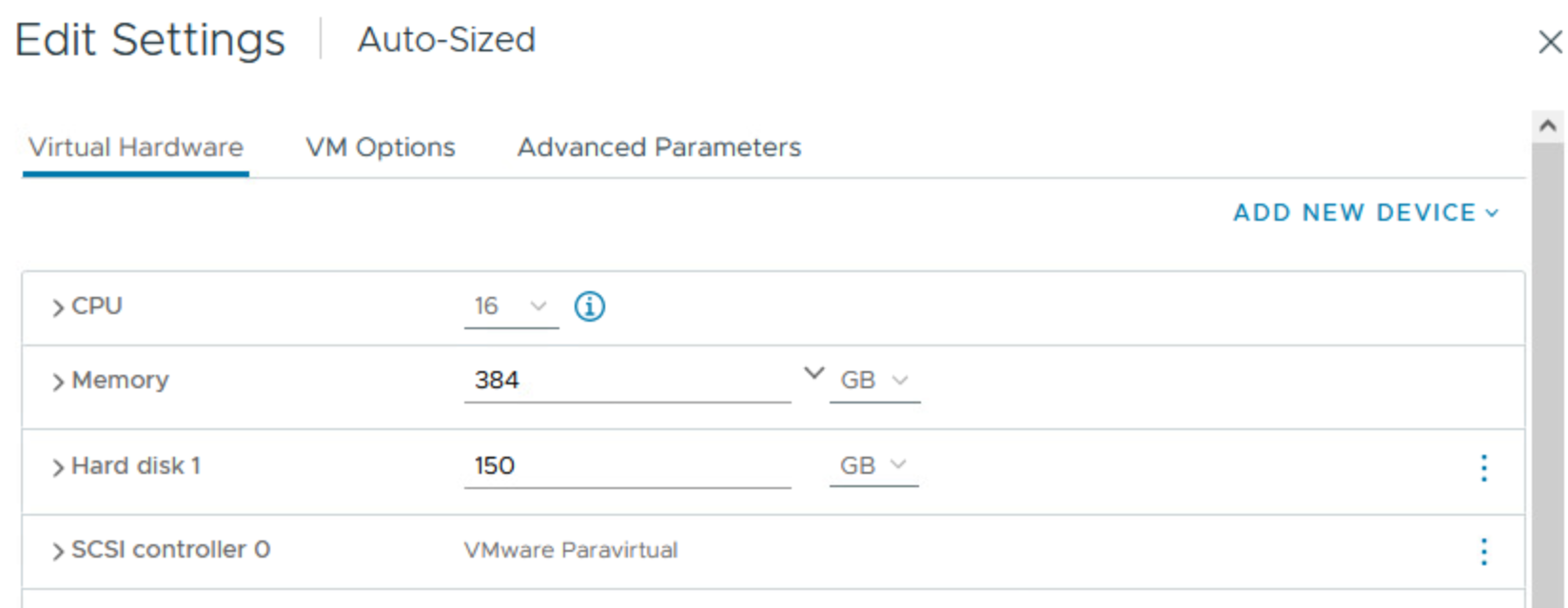
ESXi는 아래 이미지와 같이 게스트 OS에 UMA 토폴로지를 제공합니다:
그림 20. vNUMA 구성에서 메모리 크기를 고려하지 않는 ESXi
그림 21. Windows에서 본 메모리 전체 VM
이 구성에서 Windows는 16개의 CPU와 384GB RAM이 모두 하나의 NUMA 노드에 있다고 믿게 됩니다. ESXi 자체에 확인해보면 이는 사실이 아니며 정확하지도 않다는 것을 알 수 있습니다. 이로 인해 아래 이미지와 같이 16개 vCPU 중 일부의 메모리 요청이 원격 메모리에서 처리되는 상황이 발생하게 됩니다:
그림 22. 자동 vNUMA 선택으로 인해 메모리 전체 VM에 불균형한 토폴로지 생성

참고:
- LocalMem은 할당된 vCPU에 로컬로 할당된 VM의 할당된 메모리 양(~256GB)입니다.
- RemoteMem은 다른 노드에 위치한 VM의 할당된 메모리 양입니다.
이 상황은 관리자의 수동 개입이 필요한 상황으로, vNUMA 불균형과 관련된 지연 시간으로 인해 SQL Server의 쿼리 및 프로세스가 영향 받지 않기를 원할 뿐입니다.
예 3
이 예제에서는 지난 예제에서 설명한 상황을 신속하게 수정하고 이러한 불균형의 영향을 완화하는 방법을 보여드리겠습니다.
이전 예제의 주요 문제는 SQL Server 인스턴스에 vCPU보다 더 많은 메모리가 필요하다는 것이었습니다. 이는 특정 비즈니스 요구 사항 또는 기타 요구 사항 때문일 수 있으므로 요구 사항을 합리화하려고 시도하지 않겠습니다. 우리의 목표는 SQL Server 인스턴스의 비즈니스 또는 운영 요구 사항을 최적으로 지원하기 위해 vSphere에서 적절하게 구성된 가상 머신을 제공하는 것입니다.
구성을 16개의 vCPU와 384GB RAM으로 그대로 두고 VM 속성의 “VM Options” 탭으로 이동하여 “CPU Topology” 섹션으로 이동한 후 원하는 상태 구성을 반영하는 토폴로지를 ESXi에 표시하는 방법을 조정합니다.
VM의 전원을 끄고 각 소켓에 8개의 코어를 사용하여 vCPU를 두 개의 소켓으로 분할합니다.
또한 할당된 큰 메모리 풋프린트를 고려하여 두 개의 NUMA 노드를 명시적으로 구성합니다.
그림 23. vSphere 8.0의 수동 vNUMA 구성 옵션

전원을 켜면 구성 변경의 효과를 즉시 확인할 수 있습니다:
이제 게스트 운영 체제에서 두 개의 가상 NUMA 노드를 볼 수 있습니다.
그림 24. Windows에서 본 수동 vNUMA 구성

perfmon에서 할당된 RAM의 절반이 각 NUMA 노드에 할당된 것을 확인할 수 있습니다.
그림 25. 균형 잡힌 토폴로지를 제공하는 수동 vNUMA 토폴로지
이렇게 할당된 RAM을 여러 노드로 균등하게 분할하는 것은 명령줄에서 Perfmon을 쿼리하면 더 명확하게 알 수 있습니다.
그림 26. 할당된 메모리가 vNUMA 노드에 고르게 분산됨

이 프레젠테이션은 SQL Server 인스턴스의 성능을 크게 개선하는 훨씬 더 나은 프레젠테이션입니다.
예 4
이 예에서는 성능 향상 및 대칭 토폴로지에 대한 지식을 사용하여 더 큰 vCPU 풋프린트를 가진 훨씬 더 큰 VM(일명 “Monster VM”)을 생성합니다.
ESXi에 128개의 논리적 프로세서(2x32+하이퍼스레드)가 있다는 점을 염두에 두고 대략적인 계산을 해보면 각 물리적 NUMA 노드에 64개의 논리적 프로세서가 있다는 것을 알 수 있습니다. 이번에는 가상 머신에 64개 이상의 vCPU를 할당하고 메모리를 384GB로 유지하여 두 컴퓨팅 리소스가 모두 호스트의 NUMA 노드에서 물리적으로 사용할 수 있는 것보다 많도록 할 것입니다.
그림 27. 와이드 VM을 위한 자동 vNUMA 토폴로지

또한 ESXi의 기본 동작을 수용하고 이 구성에 최적이라고 판단되는 토폴로지를 할당하도록 허용합니다.
그림 28. 와이드 가상 머신에 대한 자동 vNUMA 프레젠테이션 구성

이 구성에서는 수동 관리 개입 없이도 각 NUMA 노드에 할당된 모든 메모리가 노드에 완전히 로컬이므로 모든 것이 올바르게 구성되었음을 ESXi가 알려줍니다.
그림 29. esxtop에서 본 균형 잡힌 vNUMA 프레젠테이션

또한 게스트 OS에서 ESXi가 예상 토폴로지를 노출하고 표시하는 것을 볼 수 있습니다.
그림 30: Windows에서 본 vNUMA 토폴로지
각 노드가 할당된 RAM의 절반을 가지고 있기 때문에 컴퓨팅 리소스가 NUMA 노드 간에 균등하게 분산됩니다:
그림 31. 자동 vNUMA 구성의 넓은 VM 메모리 분배
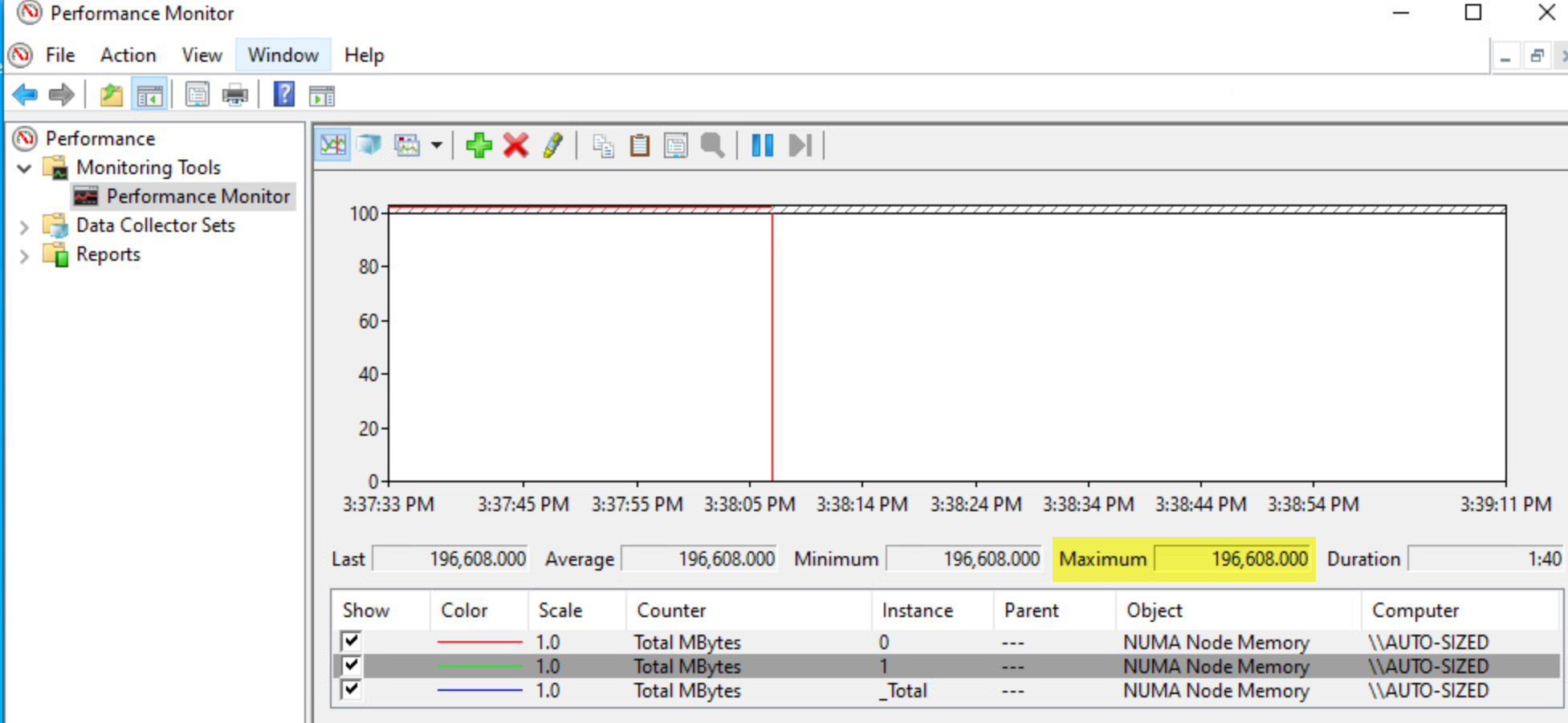
그림 32. Windows에서 본 자동 vNUMA 구성의 넓은 VM 메모리 분배

이 프레젠테이션은 SQL Server에 최적화되고 균형 잡힌 내용입니다.
이러한 자세한 예제를 통해 vSphere 8.0의 새로운 vNUMA 토폴로지 구성 옵션의 기능 및 동작을 보여 드렸습니다. 이 기능은 후속 버전에서 계속 개선되고 최적화될 것으로 예상되며, 해당 변경 사항이 있을 때마다 이 지침을 업데이트할 예정입니다.
vNUMA 확인
원하는 vNUMA 토폴로지를 정의하고 구성한 후 VM의 전원을 켜고 최종 토폴로지가 어떻게 보이는지 다시 확인합니다. VM을 호스팅하는 ESXi 호스트에서 다음 명령을 사용할 수 있습니다[36]:
vmdumper -l | cut -d \/ -f 2-5 | while read path; do egrep -oi "DICT.*(displayname.*|numa.*|cores.*|vcpu.*|memsize.*|affinity.*)= .*|numa:.*|numaHost:.*" "/$path/vmware.log"; echo -e; done그림 33. vmdumper로 NUMA 토폴로지 확인

VM vNUMA 크기 조정 권장 사항
vNUMA를 도입하면 멀티코어 VM의 문제를 극복하는 데 많은 도움이 되지만, VM의 vNUMA 크기를 조정할 때는 다음과 같은 모범 사례를 고려해야 합니다.
- 일반적으로 VM이 하나의 pNUMA 노드에 적합하고 로컬 메모리 액세스의 이점을 누릴 수 있을 때 최상의 성능이 관찰됩니다. 예를 들어, pNUMA 노드당 12개의 pCore가 있는 호스트에서 SQL Server VM의 크기를 조정하는 경우, VM은 14개의 vCPU가 할당될 때보다 12개의 vCPU가 할당될 때 더 나은 성능을 발휘할 가능성이 높습니다. 이는 할당된 메모리가 14개의 vCPU를 사용할 때보다 12개의 vCPU에 로컬로 할당될 가능성이 더 높기 때문입니다.
- 와이드 NUMA 구성이 불가피한 경우(예: 위에 설명된 시나리오 사용), 비즈니스 요구 사항에 따라 VM에 12개 이상의 vCPU가 필요한 것으로 결정된 경우 구성을 구현하기 전에 제공된 권장 사항을 다시 확인하고 광범위한 성능 테스트를 실행하는 것을 고려하십시오. 프로덕션 환경으로 전환한 후에는 중요한 CPU 카운터에 대한 모니터링을 구현해야 합니다.
게스트 내 운영 체제
현재 버전의 SQL Server는 Windows 또는 Linux 운영 체제에서 실행할 수 있습니다. 모든 경우에 이 계층에서 NUMA 구성의 가장 중요한 부분은 노출된 vNUMA 토폴로지를 다시 확인하고 설정된 기대치와 비교하는 것입니다. 노출된 NUMA 토폴로지가 예상과 다르거나 원하지 않는 경우 게스트 OS가 아닌 vSphere 계층에서 변경을 수행해야 합니다. 변경이 필요하다고 판단되는 경우 VM을 다시 시작하는 것만으로는 충분하지 않다는 점에 유의하십시오. vNUMA 토폴로지를 조정하는 방법은 이전 섹션을 참조하십시오.
Windows OS에서 NUMA 토폴로지 확인
Windows Server 2016 이상을 사용하는 경우 리소스 모니터를 통해 필요한 정보를 얻을 수 있습니다.
그림 34. Windows Server Resource Monitor NUMA 토폴로지 뷰
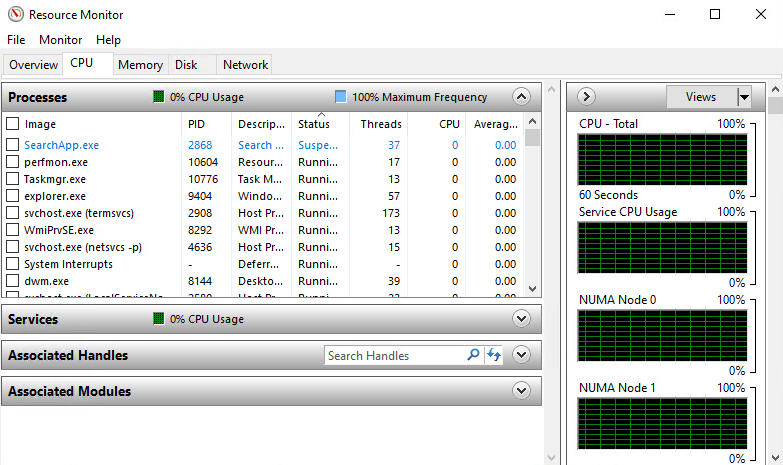
Windows Resource Monitor는 운영 체제에서 볼 때 NUMA 토폴로지를 가장 빠르게 볼 수 있는 방법입니다. 또 다른 유용한 도구로는 원래 Sysinternals에서 제공되었으나 현재는 Microsoft가 인수하여 소유하고 있는 Coreinfo가 있습니다[37].
그림 35. 24코어/2소켓 VM에 대한 NUMA 토폴로지를 보여주는 Coreinfo

Linux OS에서 NUMA 토폴로지 확인
SQL Server 2017부터 Red Hat Enterprise Linux 또는 Ubuntu[38]와 같은 선택된 Linux 운영 체제에서 SQL Server를 실행하는 것이 지원됩니다. 다음 유틸리티를 사용하여 노출된 NUMA 토폴로지를 확인할 수 있습니다.
- numactl[39]
이 유틸리티는 NUMA 토폴로지에 대한 포괄적인 정보를 제공하고 필요한 경우 NUMA 설정을 수정할 수 있는 기능을 제공합니다. 필요한 정보를 얻으려면 다음 명령을 실행합니다:
numactl -hardware그림 36. numactl을 사용하여 NUMA 토폴로지 표시하기

- dmesg 도구를 사용하여 /var/log/dmesg:
그림 37. dmesg 도구를 사용하여 NUMA 토폴로지 표시하기

NUMA도 비활성화하므로 acpi가 꺼져 있지 않은지 확인합니다: grep acpi=off /proc/cmdline
SQL Server
프로세스의 마지막 단계는 SQL Server 인스턴스에 노출된 NUMA 토폴로지를 확인하는 것입니다. 앞서 언급했듯이 SQL Server는 NUMA를 인식하는 애플리케이션이며, 이를 효율적으로 사용하려면 올바른 NUMA 토폴로지가 노출되어야 합니다. NUMA 토폴로지의 이점을 활용하려면 SQL Server Enterprise Edition이 필요합니다.
SQL Server Management Studio에서 서버 인스턴스의 속성에서 NUMA 토폴로지를 확인할 수 있습니다:
그림 38. SQL Server Management Studio에서 NUMA 정보 표시하기
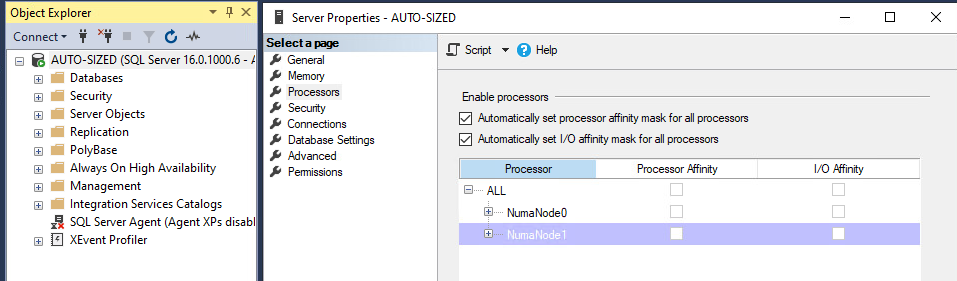
다음 명령을 사용하여 SQL Server DMV에서 직접 정보를 볼 수도 있습니다:
SELECT * FROM sys.dm_os_nodes;VM 또는 SQL Server 서비스를 다시 시작한 후 오류 로그 파일에서 추가 정보를 얻을 수 있습니다.
그림 39. 소켓당 12개 코어 VM의 자동 소프트-NUMA에 대한 오류 로그 메시지

SQL Server 자동 Soft-NUMA 및 vNUMA
SQL Server Soft-NUMA 기능은 pCPU당 코어 수의 증가에 대응하기 위해 도입되었습니다. Soft-NUMA는 하나의 NUMA 노드 내에서 사용 가능한 CPU 리소스를 소위 “soft-NUMA” 노드로 분할하는 것을 목표로 합니다. SQL Server에서 자동으로 생성되는 Soft-NUMA 토폴로지를 언뜻 보면 ESXi에서 제시하고 게스트 운영 체제에서 보는 토폴로지와 충돌한다고 생각할 수 있지만, 이 둘 사이에는 기술적 비호환성이 없습니다. 오히려 두 기능을 모두 활용하면 대부분의 워크로드에서 데이터베이스 엔진의 확장성과 성능을 더욱 최적화할 수 있는 것으로 관찰되었습니다[40].
위 이미지에서 볼 수 있듯이 SQL Server는 이 가상 머신에 할당된 98개의 vCPU를 각각 7개 코어의 14개 “NUMA 노드"로 분할했지만, 자세히 살펴보면 이 중 7개 (Soft-NUMA) 노드가 동일한 CPU 마스크 경계로 그룹화되어 있음을 알 수 있습니다. 이러한 경계에는 두 개의 경계가 있으며, 운영 체제에 제공되는 두 개의 vNUMA 토폴로지와 직접적으로 대응합니다.
SQL Server 2014 SP2부터 “Soft-NUMA"는 기본적으로 활성화되어 있으며 데이터베이스 서비스 시작을 위해 레지스트리 또는 서비스 플래그를 수정할 필요가 없습니다. SQL Server에서 파티셔닝을 시작하고 “Soft-NUMA"를 활성화하기 위한 상한선은 NUMA 노드당 8개의 코어이지만, (아래 이미지에서 볼 수 있듯이) 할당된 vCPU의 수에 따라 각 Soft-NUMA 노드는 8코어 미만을 포함할 수 있습니다(이 경우 98개의 vCPU가 각각 7코어의 14개의 작은 Soft-NUMA 노드로 나뉘어져 있음).
자동 soft-NUMA를 활성화한 결과는 에러 로그(그림 22)와 sys.dm_os_nodes 시스템 보기(그림 24)에서 확인할 수 있습니다.
그림 40: sys.dm_os_nodes 2개의 NUMA 노드와 4개의 soft-NUMA 노드가 있는 시스템에 대한 정보
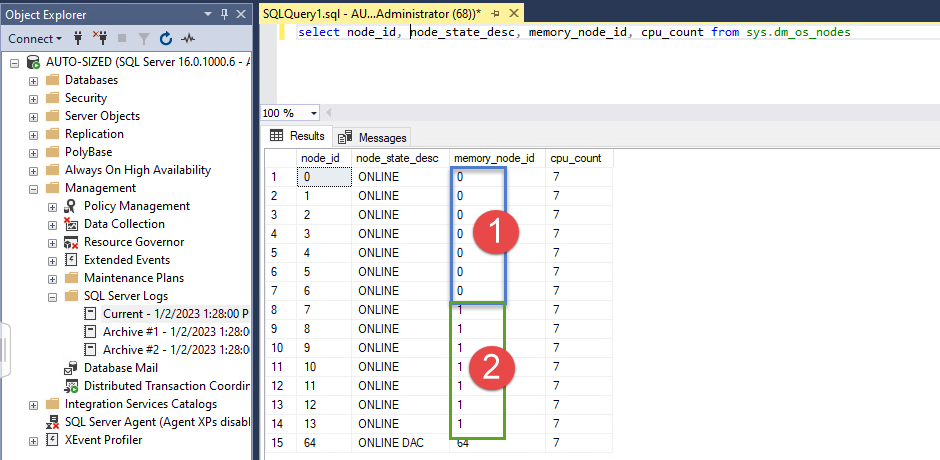
Soft-NUMA는 CPU 코어만 파티셔닝하고 CPU 선호도에 대한 메모리를 제공하지 않습니다[41]. Soft-NUMA에 대해 생성된 지연 쓰기 스레드 수는 ESXi에 의해 운영 체제에 표면화된 vNUMA 노드에 의해 결정됩니다. 결과 토폴로지가 비효율적이거나 원하는 수준보다 낮다고 판단되는 경우 관리자는 SQL 문을 통해 프로그래밍 방식으로 또는 Windows 레지스트리를 편집하여 CPU 선호도 마스크를 설정하여 구성을 수동으로 수정할 수 있습니다. 관리자는 이 변경 방법에 대한 정확한 지침과 이러한 변경이 SQL Server 인스턴스의 안정성 및 성능에 미치는 영향을 파악하기 위해 Microsoft에 문의하는 것이 좋습니다.
vSphere 8.0부터는 최신 게스트 운영 체제 및 애플리케이션에 대한 향상된 가상 CPU 토폴로지의 중요성이 커짐에 따라 가상 머신에 가상 CPU를 제공할 때 고려해야 할 사항이 변경되었습니다.
가상 머신의 가상 토폴로지는 배치 및 로드 밸런싱을 위해 게스트 OS 내에서 최적화를 가능하게 합니다. VM이 실행 중인 호스트의 기본 물리적 토폴로지와 일치하는 정확한 가상 토폴로지를 선택하는 것은 애플리케이션 성능에 매우 중요합니다.
이제 ESXi 8.0은 VM에 대한 최적의 소켓당 코어 수와 최적의 가상 L3 크기를 자동으로 선택합니다. 또한 새로운 가상 마더보드 레이아웃이 포함되어 CPU 핫플러그가 활성화된 경우 가상 디바이스 및 vNUMA 토폴로지를 위한 NUMA를 노출합니다.
이 향상된 가상 토폴로지 기능은 하드웨어 버전 20 이상의 VM에서 사용할 수 있습니다. 가상 하드웨어 버전 20은 ESXi 8.0 이상에서 생성된 VM에서만 사용할 수 있습니다.
소켓당 코어 수
이 설정을 사용하여 SQL Server Standard Edition이 할당된 모든 vCPU를 사용할 수 있고 최대 24개의 코어를 사용할 수 있도록 하는 것이 여전히 매우 일반적이므로[42], 이전 장을 읽은 후에는 라이선스 요구 사항을 충족하는 동시에 특히 vSphere 6.0 이하에서 올바른 vNUMA 토폴로지가 노출되도록 주의를 기울여야 한다는 것을 분명히 알 수 있을 것입니다.
일반적으로 소켓당 코어 비율을 구성할 때 하드웨어 구성을 반영하여 구성하고 자세한 내용은 이 문서의 NUMA 섹션을 다시 참조하십시오.
CPU Hot Plug
CPU 핫 플러그는 VM 관리자가 전원을 끄지 않고도 VM에 CPU를 추가할 수 있는 기능입니다. 이를 통해 서비스 중단 없이 CPU 리소스를 “즉시” 추가할 수 있습니다. VM에서 CPU 핫 플러그가 활성화되어 있으면 vNUMA 기능이 비활성화됩니다. 그러나 이제 이 기본 동작은 vSphere 8.0에 도입된 새로운 vNUMA 핫 추가 기능을 통해 재정의할 수 있습니다. vNUMA 핫 추가를 사용하면 SQL Server 인스턴스와 같은 NUMA 인식 애플리케이션이 가상 NUMA를 운영 체제에 표면화하여 성능 향상의 이점을 누리는 동시에 부하가 증가하는 기간 동안 VM의 CPU 리소스를 늘리는 기능에 내재된 운영 효율성을 활용할 수 있습니다.
이론적으로는 Windows Server 2022 운영 체제에 추가된 새로운 vSphere vNUMA 핫 추가 기능 및 개선 사항으로 인해 다음 참조에 설명된 문제가 더 이상 적용되지 않습니다. 이론적으로는 그렇습니다.
안타깝게도 원래의 근본적인 근본 원인은 Windows Server 2022에서 수정되었지만(참고: 이 수정 사항은 Windows Server 2019 및 이전 버전에는 백포트되지 않음), 현재 제공되는 모든 Windows 버전에서 vNUMA HotAdd를 사용하도록 설정할 때 Windows에서 유령 NUMA 노드를 생성하는 이상 현상이 계속 관찰되고 있습니다.
따라서 VMware는 모든 버전의 Windows 및 VMware vSphere에 대해, 특히 vNUMA 인식이 필요하거나 이로부터 이점을 얻을 수 있는 VM의 경우 CPU 핫 플러그(및 새로운 vNUMA HotAdd)를 사용하지 않는 것이 일반적 관행으로 유지될 것을 고객에게 계속 권장하고 있습니다. 이러한 경우에는 CPU 핫 플러그에 의존하는 것보다 VM의 CPU 크기를 적절하게 조정하는 것이 항상 더 나은 선택이며, 이 기능을 사용할지 여부는 사례별로 결정해야 하며 SQL Server 배포에 사용되는 VM 템플릿에서 구현해서는 안 됩니다.
CPU 핫 애드온이 VM 및 VM에서 호스팅되는 애플리케이션에 미치는 영향에 대한 배경 정보는 다음 문서를 참조하시기 바랍니다:
vNUMA is disabled if VCPU hot plug is enabled (2040375)
Enabling vCPU HotAdd creates fake NUMA nodes on Windows (83980)
CPU HotAdd for Windows VMs: How BADLY Do You Want It?
vSphere 8.0에서 CPU 핫 플러그 구성
이 섹션에서는 관리자가 vSphere 8.0의 새로운 CPU 핫 추가 기능을 활용하여 vSphere에서 SQL Server 인스턴스의 성능을 개선하고 관리를 간소화하는 방법에 대한 개략적인 데모를 제공합니다. 고객은 비프로덕션 환경에서 이러한 옵션을 면밀히 검증하여 각자의 특정 요구 사항에 대한 적합성을 보다 잘 파악할 것을 권장합니다.
가상 머신에 대한 가상 NUMA를 비활성화하지 않고 가상 머신에서 새로운 vNUMA 핫 추가 기능을 사용하려면 새로운 가상 머신 고급 구성 특성(numa.allowHotadd)이 필요합니다.
그림 41. CPU 핫 추가 VM 고급 구성

이 특성이 구성되면 이제 VM이 vNUMA 핫 추가를 지원할 준비가 된 것입니다.
나머지 CPU 관련 구성 옵션과 마찬가지로 이제 “VM Options” 탭의 “CPU Topology” 섹션에서 CPU 및 vCPU 핫 추가 설정을 구성할 수 있습니다. vCPU 핫 추가 설정은 “NUMA Nodes” 섹션에 있으며, 앞서 설명한 고급 구성 옵션과 함께 VM에 제공되는 가상 NUMA 노드 수를 제어합니다.
확인란을 선택하여 CPU 핫 플러그를 활성화하고 저장을 클릭합니다.
그림 42. VM에 CPU 핫 애드 활성화
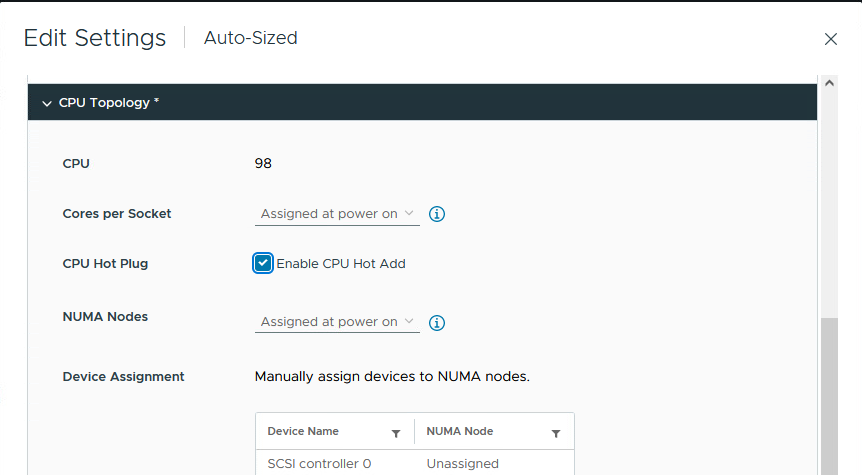
VM의 전원을 켜고 Windows에서 구성의 영향을 살펴보겠습니다.
아래 이미지에서 볼 수 있듯이 CPU 핫 추가가 사용하도록 설정되어 있음에도 불구하고 ESXi가 vNUMA 토폴로지를 VM에 표시했습니다.
그림 43: CPU 핫 추가와 함께 사용 가능한 vNUMA

위 이미지에서는 ESXi가 VM(두 개의 노드)에 대해 가장 최적의 vNUMA 토폴로지로 간주하는 것을 자동으로 구성하도록 했습니다.
예를 들어 SQLOS가 Soft-NUMA로 표시하는 것을 미러링하도록 vNUMA 표시를 변경하면 어떻게 될까요? 아래 이미지에서 결과가 동일하다는 것을 알 수 있습니다. 즉, Windows가 ESXi에 구성된 NUMA 토폴로지를 충실하게 미러링합니다.
그림 44. 수동으로 구성된 vNUMA 토폴로지
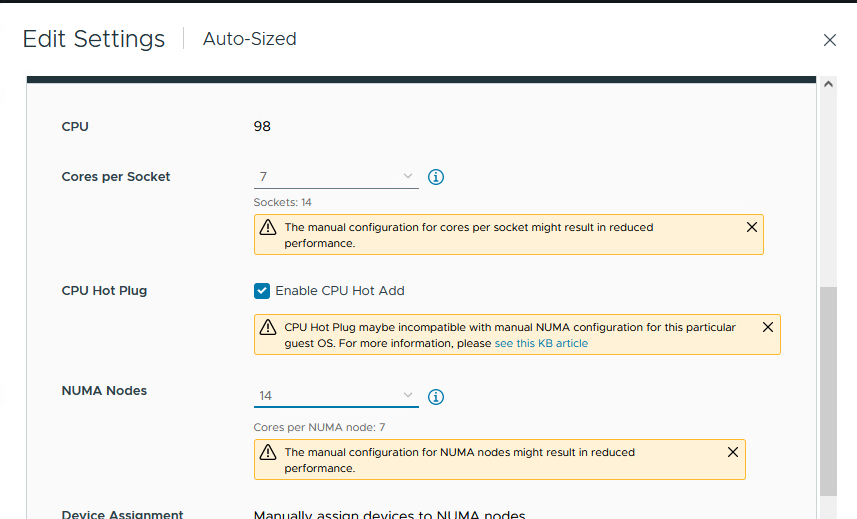
그림 45. Windows에 미러링된 정의된 토폴로지
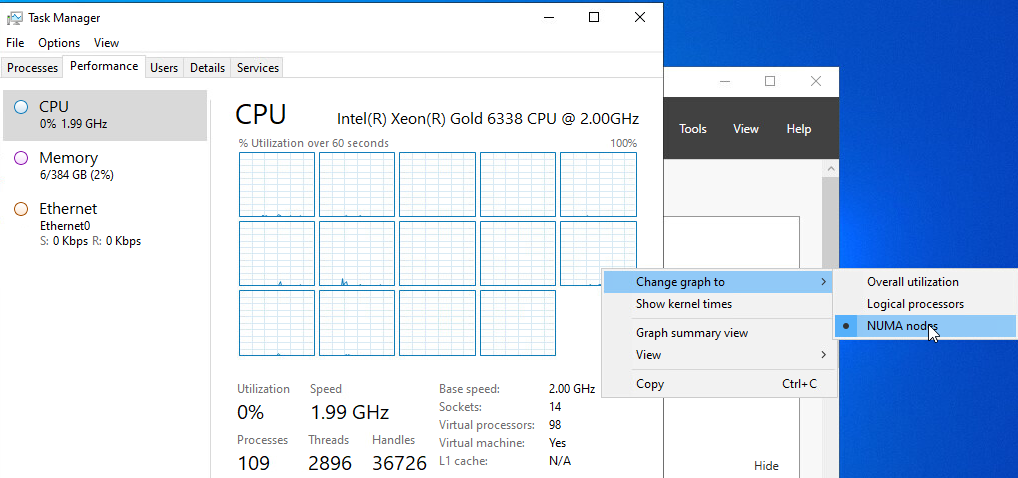
vSphere 8.0의 CPU 핫 플러그 및 “Phantom Node”
vNUMA를 사용하지 않도록 설정하는 것 외에도 Windows VM에 CPU 핫 추가를 사용하도록 설정할 때 가장 문제가 되는 문제 중 하나는 이 기능을 사용하도록 설정하면 하나 이상의 노드에 할당된 메모리가 없는 NUMA 토폴로지가 생성된다는 것입니다. 이 상태에서는 팬텀 노드의 모든 CPU가 원격 메모리를 사용하여 명령을 실행하므로 결과적으로 지연 시간과 성능 저하가 증폭됩니다. 아래 이미지에서 볼 수 있듯이 이 문제는 vSphere 8.0 및 Windows Server 2022에는 존재하지 않습니다.
그림 46. CPU HotAdd를 사용하는 “팬텀 노드” 없음

앞서 언급했듯이 이 새로운 기능을 사용하면 게스트 운영 체제 및 내부에서 호스팅되는 NUMA 인식 애플리케이션이 ESXi에 의해 표면화된 가상 NUMA 토폴로지를 인식할 수 있지만, 앞서 언급한 “팬텀 NUMA 노드” 문제로 인해 VMware는 고객이 Windows 운영 체제에서 이 기능을 활성화하지 않을 것을 권장합니다.
CPU 선호도
CPU 선호도는 VM이 상주하는 물리적 서버에서 사용 가능한 물리적 코어의 하위 집합으로 VM의 vCPU 할당을 제한합니다.
CPU 선호도는 하이퍼바이저가 물리적 서버에서 vCPU를 효율적으로 예약할 수 있는 기능을 제한하므로 운영 환경에서 사용하지 않는 것이 좋습니다. 또한 VM을 vMotion하는 기능도 사용하지 않도록 설정합니다.
VM별 EVC 모드[43]
VMware는 vSphere 버전 6.7에서 VM 수준에서 EVC(향상된 vMotion 호환성) 모드를 구성할 수 있는 기능을 도입했습니다. VM별 EVC 모드는 가상 머신의 전원을 켜고 마이그레이션하는 데 필요한 호스트 CPU 기능 집합을 결정합니다. 가상 머신의 EVC 모드는 클러스터 수준에서 정의된 EVC 모드와 독립적이며 이를 대체합니다.
SQL Server 인스턴스를 호스팅하는 가상 머신에서 EVC 모드를 가상 머신 속성으로 설정하면 DataCenter/vCenter 간 또는 여러 vSphere 기반 퍼블릭 클라우드 인프라로 가상 머신을 마이그레이션하는 동안 다운타임을 방지하는 데 도움이 될 수 있습니다.
참고: EVC 모드를 구성하면 VM에 노출되는 CPU 기능 목록이 줄어들고 SQL Server 데이터베이스 및 인스턴스의 성능에 영향을 미칠 수 있습니다.
참고: EVC 모드를 VM 속성으로 사용하려면 최소 가상 하드웨어 호환성 버전 14가 필요합니다. 모든 호스트는 이 호환성 모드에서 실행되는 VM을 지원해야 하며 최소한 vSphere 버전 6.7 이상이어야 합니다.