8.3 Fault Domains
장애 도메인 이면의 아이디어는 추가 데이터 복사본을 필요로 하지 않고 호스트(섀시 또는 랙) 그룹의 장애를 허용할 수 있다는 것입니다. 이 구현을 통해 vSAN은 가상 시스템 데이터의 복제본을 서로 다른 도메인(예: 컴퓨팅 랙)에 저장할 수 있습니다.
설계 결정 : 필요하지는 않지만 장애 도메인당 호스트 수가 동일한 장애 도메인을 구축하는 것이 좋습니다. 하드웨어 구성은 전체 클러스터에서 일관성을 유지해야 합니다. 호스트 재구성 및 데이터 균형 재조정에 영향을 미칠 때 고려할 사항을 신중하게 검토하지 않고는 이 기능을 활성화하지 마십시오.
RAID 1을 사용하고 NumberOfFailuresToTorerate = 1의 가상 시스템을 배포할 때 필요한 호스트는 2n + 1개입니다(여기서 n = NumberOfFailuresToTorerate). 즉, 1개의 장애를 허용하려면 ESXi 호스트가 3개 필요합니다. 2개의 장애를 허용하려면 5개의 호스트가 필요하고 가상 시스템이 3개의 장애(최대)를 허용하려면 7개의 호스트가 필요합니다.
RAID 5/6 소거 코딩 내결함성 방법은 추가 고려 사항을 더했습니다. 아래 차트를 참조하십시오. RAID 5 사용 시기에 대한 자세한 내용은 이 비디오를 참조하십시오.
vSAN 8 Express Storage Architecture 6개 이상의 호스트를 사용할 경우 용량 효율성을 높이기 위해 최소 3개의 호스트로 시작하고 스트라이프 크기를 4+1로 변경하거나 소규모 클러스터에 대해 2+1 정책을 지원하는 새로운 적응형 RAID 5 정책을 도입했습니다.
vSAN OSA RAID
| NumberOfFailuresToTolerate | Fault Tolerance Method | VSAN OSA or ESA | Implemented Configuration | Number of hosts required |
|---|---|---|---|---|
| 0 | RAID-1 | OSA | RAID-0 | 1 |
| 1 | RAID-1 | OSA | RAID-1 | 3 |
| 1 | RAID5/6 | OSA | RAID-5 (3+1) | 4 |
| 2 | RAID-1 | OSA | RAID-1 | 5 |
| 1 | RAID 5 | ESA | RAID-5 (2+1) | 3 |
| 1 | RAID 5 | ESA | RAID-5 (4+1) | 6 |
| 2 | RAID5/6 | OSA | RAID-6 | 6 |
| 3 | RAID-1 | OSA | RAID-1 | 7 |
vSAN 클러스터에 4개의 랙으로 분할된 12개의 호스트가 있는 경우를 예로 들어보자. 각 랙에 3개의 ESXi 호스트가 있다고 가정하자. 장애 1개를 허용하는 가상 시스템을 배포하면 두 복제본이 동일한 랙의 서로 다른 호스트에 배포될 수 있습니다.
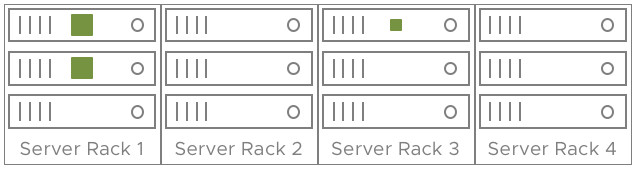
장애 도메인이 활성화되면 호스트를 그룹화하여 장애 도메인을 구성할 수 있습니다. 즉, 가상 시스템 데이터의 두 복사본/복제본이 동일한 장애 도메인에 배치되지 않습니다. 이 예에서는 미러링된 구성 요소와 감시 기능이 세 개의 랙에 분산되어 있습니다. 전체 서버 랙(장애 도메인)이 손실되어도 개체 및 가상 시스템의 가용성이 손실되지 않습니다.
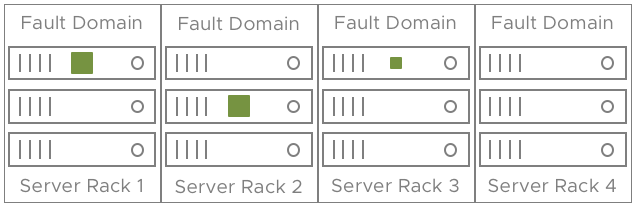
장애를 허용하는 데 필요한 장애 도메인 수를 계산하려면 이전과 동일한 수식을 사용하십시오. 장애 도메인이 있는 클러스터에 NumberOfFailuresToTorerate = 1인 가상 시스템을 배포할 때는 2n+1개 이상의 장애 도메인(스토리지에 기여하는 호스트를 1개 이상 포함)이 필요합니다. 이 방법으로 위의 표를 " hosts"을 " fault 도메인"으로 대체하여 복제하여 장애 도메인 수를 파악할 수 있습니다.
| NumberOfFailuresToTolerate | Fault Tolerance Method | Implemented Configuration | Number of Fault Domains required | Number of Fault Domains required to rebuild after failure |
|---|---|---|---|---|
| 0 | RAID-1 | RAID-0 | 1 | NA |
| 1 | RAID-1 | RAID-1 | 3 | 4 |
| 1 | RAID5/6 | RAID-5 | 4 | 5 |
| 2 | RAID-1 | RAID-1 | 5 | 6 |
| 2 | RAID5/6 | RAID-6 | 6 | 7 |
| 3 | RAID-1 | RAID-1 | 7 | 8 |
계산 리소스의 경우에도 마찬가지입니다. 이러한 시나리오에서는 장애 도메인 장애로 인해 리소스가 부족해지는 것을 방지해야 하므로 1개의 장애 도메인 가치가 있는 추가 CPU/메모리가 필요합니다.
장애가 발생하면 정책 준수의 전체 복원을 활성화하려면 장애 도메인이 추가로 필요합니다. 장애 도메인을 설계할 때는 이를 스토리지에 반영하고 오버헤드를 계산해야 합니다.
설계 결정: 매우 큰 vSAN 클러스터를 설계할 때 장애 도메인을 사용하여 가상 시스템에 속한 모든 복제본에 영향을 미치는 단일 랙 장애를 방지하는 방법을 고려하고 장애 발생 시 구성 요소를 재구성하는 데 필요한 추가 리소스 및 용량 요구 사항도 고려합니다.
환경에 대한 유지보수를 어떻게 수행할 것인지에 대한 전략과 운영 실행서가 있어야 합니다. 다음 중 하나를 위한 설계:
만약 Total Fault Domains = 정책을 충족해야 하는 필수 장애 도메인인 경우:
- 한 번에 하나의 호스트만 유지 보수 모드로 전환해야 합니다.
- 장애 도메인의 한 호스트에서 사용되는 용량은 동일한 장애 도메인의 다른 모든 호스트에서 사용 가능한 총 공간보다 작아야 합니다.
예비 용량은 다음과 같이 계산할 수 있습니다. 여기서:
D= 장애 도메인의 호스트 수 T= 유지 보수할 호스트 수(또는 ‘허용’ 값의 실패를 허용하는 호스트 수) A= 호스트당 활성 데이터 수 (호스트당 활성 데이터 x 유지 보수할 호스트 수) 에 의해 나누어진 (장애 도메인의 호스트 수 – 유지 보수 모드로 전환할 호스트) (A*T/D-T)

예:
위의 이미지를 예로 들어, RAID 6을 사용한 FTT=2 정책을 가정하여 호스트 esxi-03을 유지 보수 모드로 전환하려면 호스트 esxi-03의 데이터를 대피시킬 수 있습니다. 이 경우 해당 데이터를 수집할 수 있는 유일한 호스트는 동일한 FD 내에 있습니다. 따라서 사용 가능한 용량을 파악하려면 다음과 같이 하십시오:
재구축/relocated할 호스트당 A=3.7TB 소모 용량을 가정합니다.
(3.7TB * 호스트 1개) / (FD 내 호스트 3개 – 호스트 1개) = 3.7/(3-1) = 3.7/2
1회 가동 중단 후 남은 각 호스트의 FD에서 호스트당 1.85TB의 예비 용량 필요.
Total Fault Domains > Required Fault Domains(전체 장애 도메인)가 정책을(를):
- 상기적용방법 — 또는 —
- 하나의 호스트에서 사용하는 용량은 초과 장애 도메인에서 사용 가능한 총 공간보다 작아야 합니다.
- 가장 좋은 방법은 한 번에 한 개의 호스트를 유지 보수 모드로 전환하는 것이지만, 전체 장애 도메인을 서비스해야 하는 경우에는 두 개 이상의 장애 도메인의 호스트를 동시에 유지 보수 모드로 전환해서는 안 됩니다.
용량 공차 계산 – 여러 장애 도메인에 걸쳐
구성된 장애 도메인의 수가 정책에 표시된 대로 필요한 장애 도메인을 초과하고 장애 도메인 내에 대피된 데이터를 수집할 수 있는 용량이 부족한 경우 추가 장애 도메인에 추가 용량을 부담시킬 수 있습니다. 따라서 용량 계산에는 사용 가능한 장애 도메인의 수 또는 추가 장애 도메인의 수가 포함되어야 하며, 이러한 장애 도메인의 호스트가 유지 보수 모드의 호스트에서 데이터를 수집하는 데 필요한 여유 용량의 양을 결정해야 합니다.
예비 용량은 다음과 같이 계산할 수 있습니다. 여기서:
F= 총 장애 도메인 수 정책을 만족시키기 위해 R= 필요한 장애 도메인 수 D= 장애 도메인의 호스트 수 T= 유지 보수할 호스트 수(또는 ‘허용’ 값의 실패를 허용하는 호스트) A= 호스트당 활성 데이터 수 (호스트당 활성 데이터 x 유지 보수할 호스트 수) 에 의해 나누어진 (총 장애 도메인 – 장애 도메인 필요) x(각 장애 도메인의 호스트 수)
(A*T) / ((F-R)*D)

예:
위의 이미지를 예로 들면, FTT=2 및 RAID6 정책을 다시 사용하여 FD3에서 유지보수를 위해 2개의 호스트를 중단할 수 있지만 장애 도메인 내에서 호스트 장애가 발생할 경우 영향을 받는 데이터를 재구축할 수 있는 충분한 용량이 있다면 다음과 같이 용량을 계산할 수 있습니다:
재구축/relocated할 호스트당 A=3.7TB 소모 용량을 가정합니다.
(3.7TB * 3개의 호스트) / ((총 8FD – 6FD 필요) * FD당 3개의 호스트) (3.7*3)/((8-6)3) 11.1/(23) 11.1/6 FD #3을 배출하기 위해 나머지 FD 2개의 호스트 6개 각각에 필요한 1.85TB 예비 용량
추가 컨텐츠: Considerations using vSAN fault domains" 읽기