6.5 Policy Design Decisions
관리자는 이러한 스토리지 기능이 vSAN의 스토리지 용량 소비에 어떤 영향을 미치는지 이해해야 합니다.
vSAN ESA - Auto-Policy management
vSAN 8 U1은 기본 스토리지 정책을 사용하는 데이터가 가장 최적의 복원력을 갖춘 방식으로 저장되도록 보장하는 방법을 ESA에 도입했습니다. 클러스터를 강조 표시하고 Configure > vSAN Services > Storage를 클릭한 다음 “Edit"을 클릭하고 “Auto-Policy management"를 활성화하여 클러스터 서비스를 사용하도록 설정할 수 있습니다.
최적화된 스토리지 정책에서 사용하는 정책 설정은 클러스터 유형, 클러스터의 호스트 수, 클러스터에서 Host Rebuild Reserve (HRR) 용량 관리 기능이 활성화되어 있는지 여부에 따라 달라집니다. 이 세 가지 중 하나라도 변경하면 vSAN에서 클러스터별로 최적화된 스토리지 정책을 제안하여 조정합니다.
- 표준 vSAN 클러스터(호스트 재구축 예약이 해제된 상태):
- HRR이 없는 호스트 3개: RAID-1 사용 시 FTT=1
- HRR이 없는 호스트 4개: RAID-5(2+1)를 사용하여 FTT=1
- HRR이 없는 호스트 5개: RAID-5(2+1)를 사용하여 FTT=1
- HRR이 없는 호스트 6개 이상: RAID-6(4+2)을 사용하여 FTT=2
- 표준 vSAN 클러스터(호스트 재구축 예약 사용)
- 호스트 3개와 HRR: (호스트 3개에서는 HRR이 지원되지 않음)
- 4개 호스트와 HRR: RAID-1을 사용하는 FTT=1
- 5개의 호스트와 HRR: RAID-5(2+1)를 사용하여 FTT=1
- 6개의 호스트와 HRR: RAID-5(4+1)를 사용하여 FTT=1
- 7개 이상의 호스트(HRR): RAID-6(4+2)을 사용하는 FTT=2
- vSAN 스트레치 클러스터:
- 각 사이트에 3개의 데이터 호스트: 보조 수준의 복원력을 위해 RAID-1 미러링을 사용하는 FTT=1의 사이트 수준 미러링
- 각 사이트에 호스트 4개: 보조 복원력을 위해 RAID-5(2+1)를 사용하는 FTT=1의 사이트 수준 미러링(보조 복원력 수준).
- 각 사이트에 호스트 5개: 보조 복원력을 위해 RAID-5(2+1)를 사용하는 FTT=1의 사이트 수준 미러링(보조 복원력 수준).
- 각 사이트에 호스트 6개 이상: 보조 복원력을 위해 RAID-6(4+2)을 사용하는 FTT=2의 사이트 수준 미러링(보조 복원력 수준).
- vSAN 2-노드 클러스터:
- 데이터 호스트 2개: RAID-1을 사용하는 호스트 수준 미러링
이 정책에 대한 자세한 내용은 이 블로그를 참조하십시오.
오브젝트당 디스크 스트라이프 수/스트라이프 너비
Number Of Disk Stripes Per Object(일반적으로 스트라이프 너비라고 함)는 스토리지 오브젝트의 각 복제본이 분산되는 최소 용량 디바이스 수를 정의하는 설정입니다. vSAN은 실제로 정책에 지정된 수보다 더 많은 스트라이프를 생성할 수 있습니다.
특정 가상 머신은 I/O 집약적이고 다른 가상 머신은 그렇지 않은 경우 스트라이핑이 성능에 도움이 될 수 있습니다. 스트라이핑을 사용하면 가상 머신의 데이터가 더 많은 드라이브에 분산되어 해당 가상 머신이 경험하는 전체 스토리지 성능에 기여합니다. 하이브리드의 경우, 이러한 스트라이핑은 자기 디스크에 걸쳐 이루어집니다. 올플래시의 경우 스트라이핑은 용량 계층을 구성하는 모든 플래시 디바이스에 걸쳐 이루어집니다.
vSAN 7 업데이트 1에서는 스트라이핑이 처리되는 방식에 여러 가지 변경 사항이 적용되었습니다:
- 2TB를 초과하는 오브젝트의 경우 첫 번째 2TB를 초과하는 구성 요소는 최대 스트라이프 폭을 3으로 줄입니다.
- 이제 RAID 5는 기본적으로 스트라이프 폭이 4로 간주되고 RAID 6은 스트라이프 폭이 6으로 간주됩니다.
- 가능하면 클러스터 레벨 오브젝트 관리자는 R0 리프의 스트라이프를 다른 디스크 그룹에 배치하려고 노력합니다. 이렇게 하면 중복 제거가 활성화된 클러스터에서 스트라이프가 동일한 디스크 그룹에 배치되어 실질적인 이점을 제공하지 못하는 시나리오를 방지할 수 있습니다.
그러나 애플리케이션이 특별히 I/O 집약적이지 않거나 가상 머신의 데이터가 이미 다른 I/O 집약적 가상 머신을 서비스하는 데 바쁜 디바이스에 분산되어 있는 경우에는 스트라이핑이 성능에 도움이 되지 않을 수 있습니다.
그러나 대부분의 경우 스트라이핑으로 인해 성능 문제가 완화될 수 있는 경우가 아니라면 스트라이핑을 기본값인 1로 두는 것이 좋습니다. 스트라이프 폭의 기본값은 1이고 최대값은 12입니다.
Stripe Width - 크기 조정 고려 사항(OSA)
Stripe Width 및 vSAN ESA에 대한 자세한 내용은 이 블로그를 참조하십시오.
스트라이프 폭과 관련하여 두 가지 주요 크기 조정 고려 사항이 있습니다. 첫 번째 고려 사항은 요청된 스트라이프 폭을 수용하기에 충분한 물리적 디바이스가 여러 호스트와 클러스터 전체에 있는지 여부이며, 특히 수용해야 할 NumberOfFailuresToTolerate 값도 있는지 여부입니다.
두 번째 고려 사항은 스트라이프 너비에 대해 선택한 값이 상당한 수의 구성 요소를 필요로 하고 호스트 구성 요소 수를 소비하는지 여부입니다. 이 두 가지 모두 vSAN 설계의 일부로 고려해야 하지만, 온-디스크 포맷 v2를 사용하는 6.0에서 최대 구성 요소 수가 증가했다는 점을 고려하면 더 이상 큰 우려 사항은 아닙니다. 나중에 몇 가지 작업 예제를 통해 vSAN 클러스터를 설계할 때 이러한 요소를 고려하는 방법을 살펴보겠습니다.
Flash Read Cache Reservation
앞서 Flash Read Cache Reservation 사이징에 대한 10% 규칙에 대해 언급했습니다. 이는 하이브리드 구성에서는 읽기 캐시 및 쓰기 버퍼로, 올플래시 구성에서는 쓰기 버퍼로만 사용되며 모든 가상 머신에 공평하게 분배됩니다. 그러나 VM 스토리지 정책 설정 플래시 읽기 캐시 예약을 사용하면 읽기 캐시의 일부를 하나 이상의 가상 머신에 전용으로 할당할 수 있습니다.
참고: 이 정책 설정은 하이브리드 구성에만 해당됩니다. 올플래시 구성에서는 캐싱 메커니즘의 변경 사항과 올플래시 구성에 읽기 캐시가 없기 때문에 지원되지 않거나 관련성이 없습니다.
하이브리드 구성의 경우 이 설정은 스토리지 오브젝트에 대해 예약해야 하는 읽기 플래시 용량을 정의합니다. 이 설정은 가상 머신 디스크 오브젝트의 논리적 크기의 백분율로 지정됩니다. 이 설정은 특별히 식별된 읽기 성능 문제를 해결하는 데만 사용해야 합니다. 다른 가상 머신 오브젝트는 이 예약된 플래시 캐시 용량을 사용하지 않습니다.
예약되지 않은 플래시는 모든 객체 간에 공평하게 공유되므로 특정 성능 문제가 관찰되지 않는 한 플래시 예약을 변경하지 않는 것이 좋습니다. 기본값은 0%로, 오브젝트에 예약된 읽기 캐시가 없지만 다른 가상 머신과 공유함을 의미합니다. 최대 값은 100%로, 예약된 읽기 캐시의 양이 스토리지 오브젝트(VMDK)와 동일한 크기임을 의미합니다.
Flash Read Cache Reservation - 크기 조정 고려 사항
VM 스토리지 정책에서 읽기 캐시 예약 요구 사항을 설정할 때는 주의를 기울여야 합니다. 특히 씬 프로비저닝을 사용하는 경우 사용자에게 플래시 읽기 캐시 예약 수치가 작아 보일 수 있지만 모든 SSD 리소스를 쉽게 소진할 수 있습니다(VM 스토리지 정책 용어에서 씬 프로비저닝을 오브젝트 공간 예약이라고 함).
플래시 읽기 캐시 예약 구성 예
이 하이브리드 vSAN 예제에서 고객은 모든 가상 머신 디스크에 대해 VM 스토리지 정책 - 플래시 읽기 캐시 예약을 5%로 설정했습니다. 하이브리드 구성에서 플래시의 70%는 읽기 캐시를 위해 따로 설정됩니다.
씬 프로비저닝을 통해 고객은 오버프로비저닝하여 실제 공간보다 더 많은 논리적 주소 공간을 확보할 수 있습니다. 이 예에서 고객은 물리적 공간보다 두 배 많은 논리적 공간(200%)을 씬 프로비저닝했습니다.
관리자가 요청한 플래시 읽기 캐시 예약을 계산하여 호스트에서 사용 가능한 총 플래시 읽기 캐시와 비교하면 다음과 같은 내용이 표시됩니다:
VM이 소비하는 총 디스크 공간 X
- 사용 가능한 총 플래시 읽기 캐시: (X의 10%의 70%) = X의 7%
- 요청된 플래시 읽기 캐시 예약: (X의 200% 중 5%) = X의 10% => X의 10%가 X의 7%보다 큼
따라서 씬 프로비저닝을 사용하여 스토리지 공간을 과도하게 커밋하는 경우 캐시 예약 설정에 부정적인 영향을 미치지 않도록 세심한 주의를 기울여야 합니다. 캐시 예약이 읽기 캐시를 모두 사용하면 성능에 부정적인 영향을 미칠 수 있습니다.
설계 고려 사항: 플래시 읽기 캐시 예약은 신중하게 사용해야 합니다. 잘못된 구성 또는 잘못된 계산으로 인해 일부 가상 머신에 읽기 캐시가 과도하게 할당되고 다른 가상 머신은 고갈될 수 있습니다.
Force Provisioning
강제 프로비저닝 정책을 사용하면 가상 머신을 처음 배포하는 동안 vSAN이 NumberOfFailuresToTolerate (FTT) , NumberOfDiskStripesPerObject (SW) , FlashReadCacheReservation (FRCR) 정책 설정을 위반할 수 있습니다.
vSAN은 모든 요구 사항을 충족하는 배치를 찾으려고 시도합니다. 그렇지 못한 경우 요구 사항을 FTT=0, SW=1, FRCR=0으로 줄인 훨씬 더 간단한 배치를 시도합니다. 즉, vSAN은 미러가 하나뿐인 오브젝트를 생성하려고 시도합니다. 모든 OSR(ObjectSpaceReservation) 정책 설정은 계속 적용됩니다.
vSAN은 충족할 수 없는 요구 사항을 단순히 줄이는 개체의 배치를 정상적으로 찾으려고 시도하지 않습니다. 예를 들어 개체가 FTT=2를 요청하는 경우 이를 충족할 수 없는 경우 vSAN은 FTT=1을 시도하지 않고 즉시 FTT=0을 시도합니다.
마찬가지로 요구 사항이 FTT=1, SW=10이었지만 vSAN에 SW=10을 수용할 수 있는 충분한 용량의 디바이스가 없는 경우 FTT=1, SW=1 정책이 성공했을지라도 FTT=0, SW=1로 되돌아갑니다.
또 다른 고려 사항이 있습니다. 관리자가 강제 프로비저닝의 동작을 잘 이해하지 못하면 용량 문제가 발생할 수 있습니다. 여러 가상 머신이 강제 프로비저닝되었지만 리소스 부족으로 인해 현재 개체의 복제본이 하나만 인스턴스화된 경우 새 호스트 또는 새 디스크 추가를 통해 해당 리소스를 사용할 수 있게 되면 vSAN이 해당 가상 머신을 대신하여 리소스를 소비합니다.
이 옵션을 사용하여 가상 시스템을 강제 프로비저닝하는 관리자는 클러스터에서 추가 리소스를 사용할 수 있게 되면 가상 시스템의 정책 설정을 충족하기 위해 vSAN이 즉시 이러한 리소스를 사용할 수 있다는 점을 알고 있어야 합니다.
주의 : 또 다른 특별한 고려 사항은 전체 데이터 마이그레이션 모드에서 유지 관리 모드로 전환하는 경우와 vSAN 6.0에 도입된 데이터 마이그레이션을 통한 디스크/디스크 그룹 제거와 관련이 있습니다. 강제 프로비저닝으로 인해(초기 배치 또는 정책 재구성이 정책 요구 사항을 충족하지 못하여) 현재 개체가 규정을 준수하지 않는 경우 해당 개체의 “전체 데이터 제거"는 실제로 “접근성 보장"과 같이 작동하며, 즉 제거로 인해 개체의 가용성이 감소하여 더 높은 위험에 노출될 수 있습니다. 이는 강제 프로비저닝을 사용할 때 중요한 고려 사항이며, 규정을 준수하지 않는 개체에 대해서만 적용됩니다.
모범 사례 : 새 리소스를 추가하기 전에 리소스 부족으로 인해 규정을 준수하지 않는 가상 머신이 있는지 확인하세요. 이렇게 하면 새 리소스가 vSAN에서 즉시 소비되는 이유가 설명됩니다. 또한 전체 데이터 마이그레이션을 수행하기 전에 강제 프로비저닝으로 인해 비규격 가상 머신이 있는지 확인합니다.
Object Space Reservation
관리자는 기존 SAN 또는 NAS 어레이의 오버 커밋을 모니터링해야 하는 것처럼 vSAN의 스토리지 오버 커밋을 항상 인지하고 있어야 합니다.
기본적으로 vSAN에 배포된 가상 머신 스토리지 개체는 씬 프로비저닝됩니다. 이 기능인 OSR(ObjectSpaceReservation)은 가상 머신을 프로비저닝할 때 예약(씩 프로비저닝)해야 하는 스토리지 오브젝트의 논리적 크기 비율을 지정합니다. 나머지 스토리지 개체는 씬 프로비저닝된 상태로 유지됩니다. 기본값은 0%로, 개체가 씬으로 배포됨을 의미합니다. 최대값은 100%로, 개체의 공간이 완전히 예약되어 있으며, 이는 전체 씩 프로비저닝된 것으로 생각할 수 있습니다. 기본값은 0%이므로 정책에서 명시적으로 ObjectSpaceReservation에 대한 요구 사항을 지정하지 않는 한 vSAN에 배포된 모든 가상 머신은 씬 디스크로 프로비저닝됩니다. ObjectSpaceReservation을 지정하면 해당 정책과 연결된 스토리지 개체의 일부가 예약됩니다.
vSAN에는 eager-zeroed 씩 포맷이 없습니다. OSR을 사용하면 lazy-zeroed 씩과 유사하게 작동합니다.
과도한 커밋을 방지하는 여러 가지 안전 장치가 있습니다. 예를 들어, 클러스터의 필요한 호스트 수에 걸쳐 복제본 또는 스트라이프 폭 정책 설정을 충족하는 데 필요한 스토리지 용량이 충분하지 않은 경우 다음과 같은 경고가 표시됩니다.
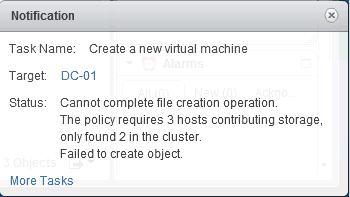
Monitor > vSAN > Disk Management 는 클러스터에서 사용된 용량을 보여줍니다.
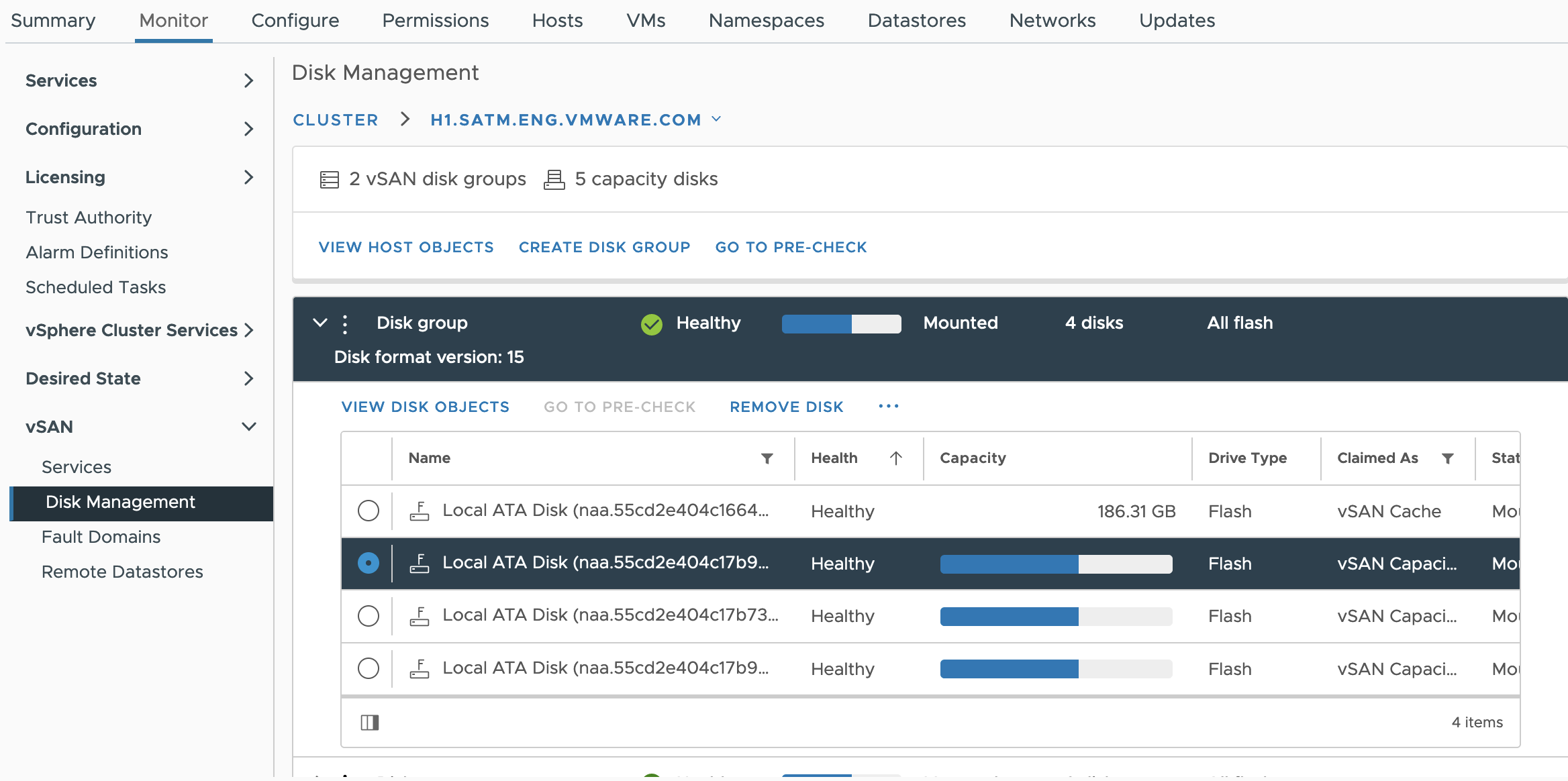
설계 고려 사항 : 복제본 생성은 vSAN 데이터스토어의 용량을 계산할 때 고려되지만, 씬 프로비저닝 오버 커밋은 vSAN에서 가상 머신을 프로비저닝할 때 크기 계산에서 고려해야 하는 사항입니다.
IOP Limit for Object
관리자가 오브젝트 또는 가상 머신에 사용할 수 있는 최대 IOPS 양을 제한하려는 경우가 있습니다. 이 기능의 주요 사용 사례는 두 가지입니다.
- 노이즈가 많은 이웃 워크로드가 더 많은 성능을 사용해야 하는 다른 워크로드에 영향을 미치지 않도록 방지합니다.
- 동일한 리소스 풀을 사용하여 계층화된 서비스 오퍼링의 일부로 인위적인 서비스 표준을 생성합니다.
기본적으로 vSAN은 수요에 따라 성능을 동적으로 조정하고 사용 가능한 리소스에 공정한 가중치를 부여하려고 합니다. 이 기능인 IopLimitForObject는 개체에 사용할 수 있는 성능의 양을 제한합니다. 이는 32KB 블록 크기로 정규화됩니다. 16KB로 읽거나 쓰는 가상 머신은 32KB 크기의 작업을 수행하는 가상 머신과 동일하게 취급됩니다. 그러나 64KB 읽기 또는 쓰기는 두 개의 개별 작업으로 처리되므로 구성된 IOP 제한의 절반이 수행된 작업 수로 간주됩니다.
Deactivate Object Checksum
이 정책은 vSAN OSA에서만 작동합니다.
오브젝트 체크섬은 vSAN 6.2에 정책으로 도입되었습니다. 읽기 또는 쓰기 작업 중에 메모리, 드라이브 등의 하드웨어/소프트웨어 구성 요소로 인한 손상을 감지하는 기능을 활성화합니다.
오브젝트 체크섬은 vSAN 파일 시스템 버전 3에 상주하는 오브젝트에 대해 기본적으로 활성화됩니다. 모든 읽기에 대해 체크섬을 확인하고 스크러버는 1년 이내에 읽지 않은 모든 블록을 검사합니다. 스크러버 일정을 더 자주 실행하도록 조정할 수 있지만 백그라운드 디스크 IO가 증가할 수 있습니다. vSAN 7 U2에서 이 디스크 스크러빙 빈도는 2주에 한 번 발생하며 작업 중 성능에 미치는 영향은 미미합니다(작업이 실행되는 동안 성능에 미치는 영향은 2% 이하입니다).
오브젝트 체크섬은 디스크 IO, 메모리 및 컴퓨팅 오버헤드가 적으며 체크섬 스토리지 정책을 사용하여 오브젝트별로 비활성화할 수 있습니다.
vSAN ESA Compression
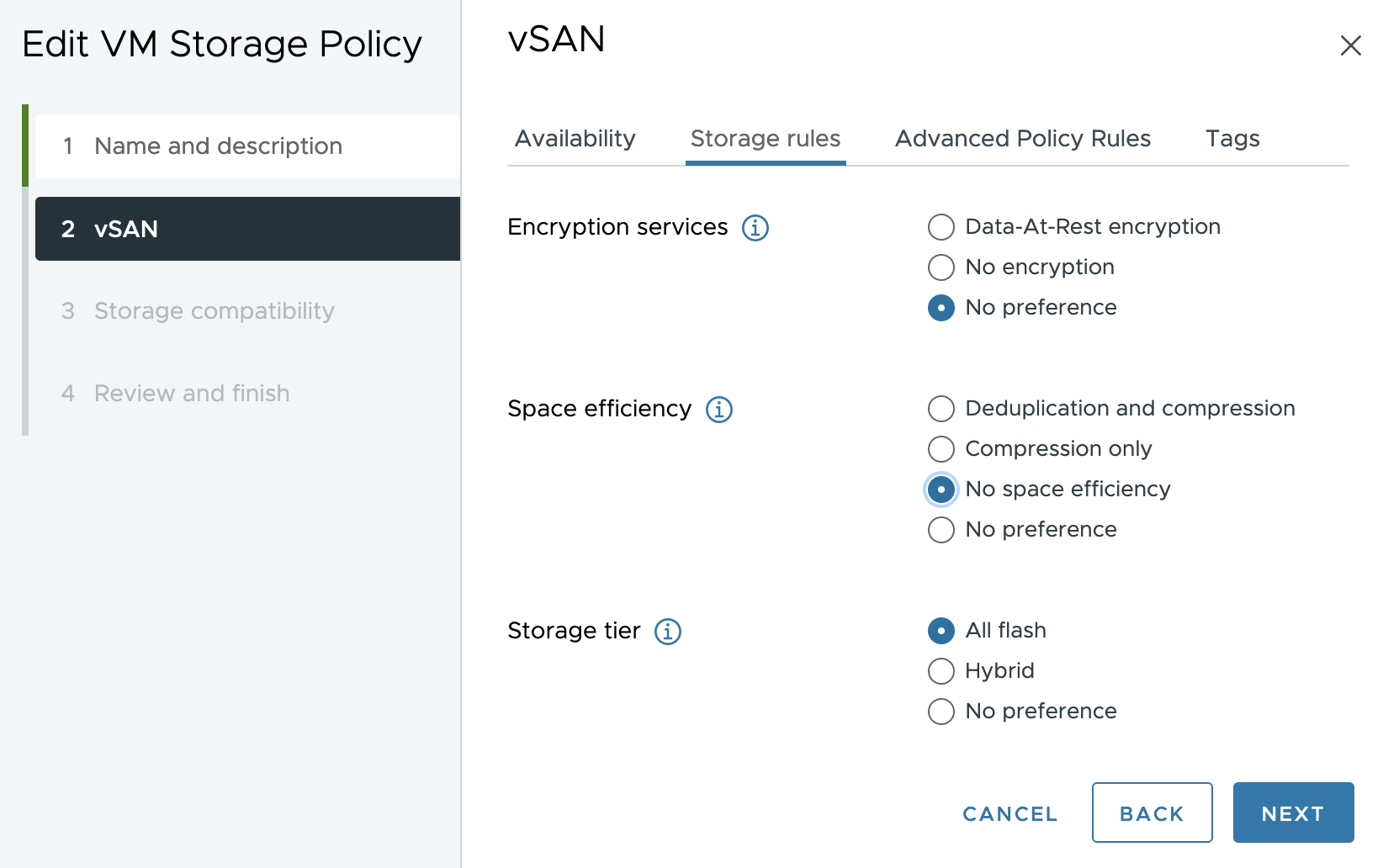
VSAN 8 Express Storage Architecture는 기본적으로 생성된 모든 가상 머신에 대해서만 압축을 사용하도록 설정합니다. 선택적으로 SPBM 정책을 사용하여 가상 머신의 새로운 쓰기에 대해 압축을 비활성화할 수 있습니다. 이 새로운 압축 시스템은 기존 압축 시스템보다 최대 4배 더 효율적이며 최대 8배까지 압축할 수 있습니다. 압축을 활성화하면 성능이 향상되므로 압축을 활성화하는 것이 좋습니다. 이제 데이터가 네트워크를 통해 전송되기 전에 압축되므로 잠재적으로 처리량이 증가하고 네트워킹 경합이 줄어듭니다. 가상 머신에서 압축을 사용하지 않도록 설정해도 데이터가 다시 쓰여지는 것은 아니며 단순히 새 쓰기에 대한 압축이 중지됩니다. vSAN ESA 압축을 사용하지 않도록 설정하려면 “No space efficiency” 스토리지 규칙 SPBM 정책을 선택합니다(아래 이미지 참조).
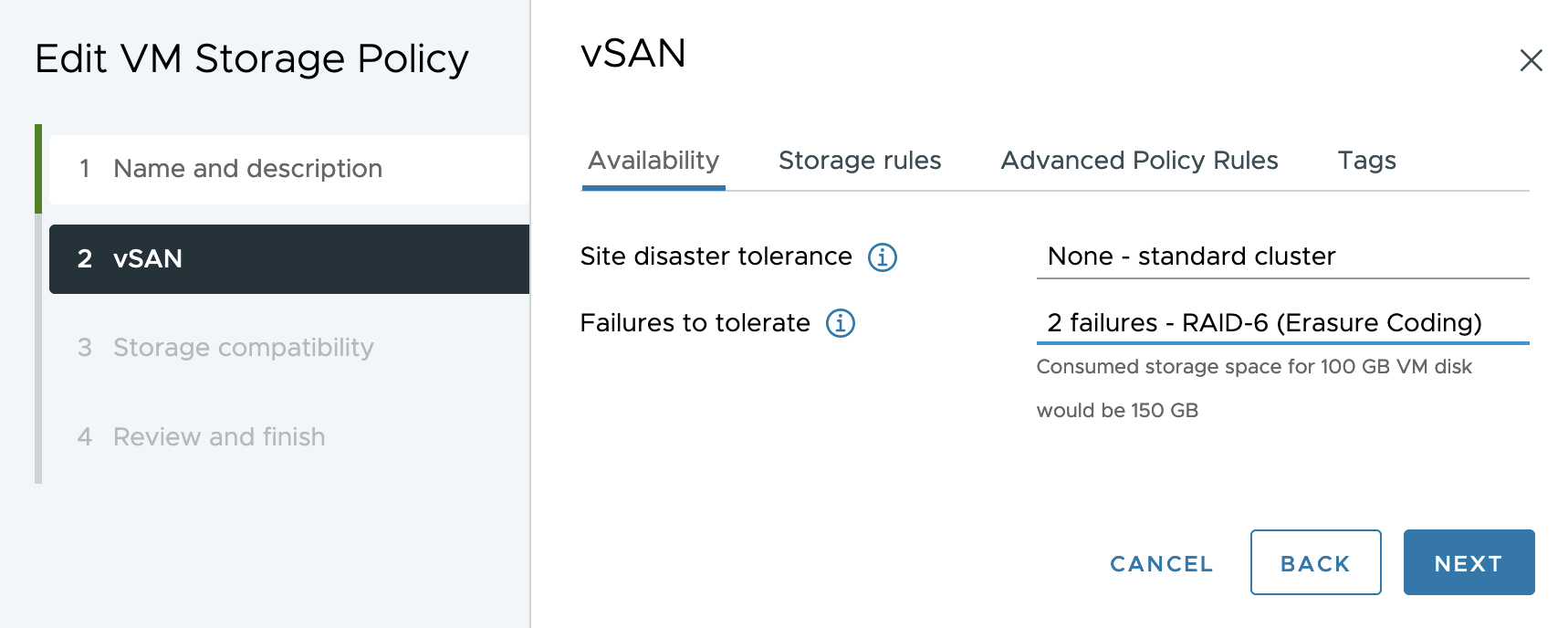
Failure Tolerance Method (vSAN 8)
“Failure Tolerance Method” 및 “Failures to Tolerate” 정책이 복원력 옵션을 선택하는 단일 옵션으로 통합되었습니다.
Failure Tolerance Method (vSAN OSA Prior to vSphere 8) 와 Number of Failures to Tolerate Policies
RAID-1(미러링)이 내결함성 방법으로 사용되었습니다. vSAN 6.2는 올플래시 구성에 RAID-5/6(이레이저 코딩)을 추가합니다. 미러링 기술은 성능이 가장 중요한 워크로드에서 탁월한 성능을 발휘하지만 필요한 용량 측면에서 비용이 많이 듭니다. RAID-5/6(이레이저 코딩) 데이터 레이아웃은 RAID-1(미러링)보다 적은 용량을 소비하면서 동일한 수준의 가용성을 보장하도록 구성할 수 있습니다.
RAID-5/6(이레이저 코딩)은 스토리지 정책 규칙으로 구성되며 개별 가상 디스크 또는 전체 가상 머신에 적용할 수 있습니다. 규칙 집합의 내결함성 방법은 RAID5/6(이레이저 코딩)으로 설정해야 합니다.
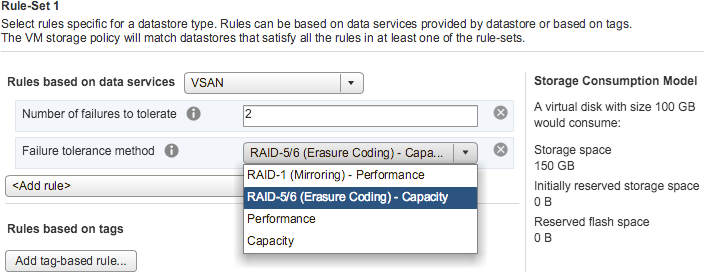
Number of Failures To Tolerate (OSA)
NumberOfFailuresToTolerate 정책 설정은 모든 가상 머신 또는 개별 VMDK에 적용할 수 있는 가용성 기능입니다. 이 정책은 vSAN의 스토리지 용량을 계획하고 크기를 조정할 때 중요한 역할을 합니다. 가상 머신의 가용성 요구 사항에 따라 가상 머신 스토리지 정책에 정의된 설정에 따라 가상 머신 용량의 최대 4배까지 소비될 수 있습니다.
허용되는 장애가 “n"인 경우 개체의 “n+1” 복사본이 생성되고 스토리지에 기여하는 “2n+1” 호스트가 필요합니다. NumberOfFailuresToTolerate의 기본값은 1입니다. 즉, 가상 머신을 배포할 때 정책을 선택하지 않더라도 가상 머신 데이터의 복제본이 하나씩 생성됩니다. NumberOfFailuresToTolerate의 최대 값은 3입니다.
vSAN 6.0에는 장애 도메인 개념이 도입되었습니다. 이를 통해 vSAN은 호스트 장애뿐만 아니라 랙, 스위치 및 전원 공급 장치 장애와 같은 환경 장애도 여러 위치에 데이터의 복제본 복사본을 배치하여 허용할 수 있습니다. 장애 도메인으로 작업할 때 “n"개의 장애를 허용하려면 “n+1"개의 오브젝트 사본이 다시 생성되지만 이제는 “2n+1"개의 장애 도메인이 필요합니다. 각 장애 도메인에는 스토리지에 기여하는 호스트가 하나 이상 포함되어야 합니다. 결함 도메인에 대해서는 곧 자세히 설명하겠습니다.
장애 허용 크기 고려 사항
NumberOfFailuresToTolerate를 1로 설정하면 클러스터 전체에 가상 머신 또는 개별 VMDK의 복제본 미러 복사본이 두 개 생성됩니다. 2로 설정하면 미러 복사본 3개가 생성되고, 3으로 설정하면 복사본 4개가 생성됩니다.
FTT=1의 경우 스토리지 오버헤드는 2배가 아닌 1.33배가 됩니다. 이 경우 20GB VMDK는 기존에 RAID-1에서 사용하던 40GB 대신 27GB를 사용하게 됩니다.
FTT=2의 경우 스토리지 오버헤드는 3배가 아닌 2배가 됩니다. 이 경우 20GB VMDK는 60GB 대신 40GB를 사용하게 됩니다.
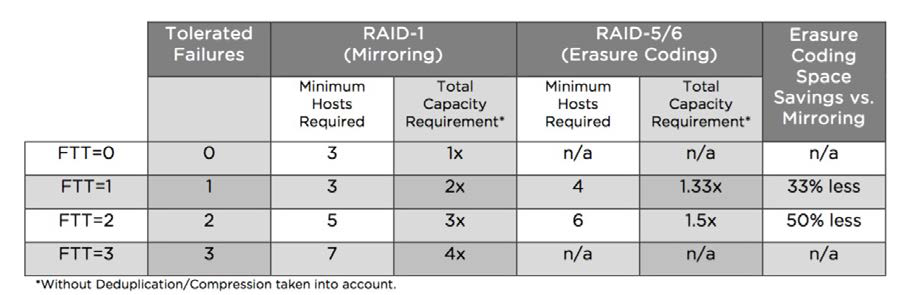
이레이저 코딩은 미러링보다 용량을 크게 절약할 수 있지만, 이레이저 코딩에는 추가적인 오버헤드가 발생한다는 점을 고려하는 것이 중요합니다. 이는 오늘날 모든 스토리지 플랫폼에서 공통적으로 발생합니다. 이레이저 코딩은 올플래시 vSAN 구성에서만 지원되므로 플래시 디바이스의 고유한 성능으로 인해 대부분의 사용 사례에서 레이턴시 및 IOPS에 미치는 영향은 무시할 수 있을 정도로 미미합니다.
이레이저 코딩을 통해 이점을 얻을 수 있는 워크로드에 대한 자세한 내용은 VMware vSAN Space Efficiency Technologies 을 참조하십시오.